Konfidenzintervall für die Erfolgswahrscheinlichkeit der Binomialverteilung
Ein Konfidenzintervall für die Erfolgswahrscheinlichkeit der Binomialverteilung ist ein Konfidenzintervall (Vertrauensbereich) für den unbekannten Parameter der Binomialverteilung (nach Beobachtung von Treffern in einer Stichprobe der Größe ).






Hierbei ist zu beachten, dass insbesondere das Standardintervall teilweise auch negative Werte einschließt, was nicht daran liegt, dass diese möglich sind, sondern der Einfachheit des nicht auf die Binomialverteilung angepassten Modelles geschuldet ist.
Exakte Konfidenzintervalle erhält man unter Zuhilfenahme der Binomialverteilung. Es gibt aber auch Näherungsmethoden, die (meistens) auf der Approximation der Binomialverteilung durch die Normalverteilung basieren.[1]
Einführendes Beispiel
[Bearbeiten | Quelltext bearbeiten]Um den unbekannten relativen Anteil einer politischen Partei A in der Wählerschaft zu schätzen, werden in einer Meinungsumfrage Personen befragt, ob sie die Partei A wählen werden. Das exakte Vorgehen ist: Wir wählen 400 Mal eine zufällige Person aus der Wählerschaft aus und befragen diese. Dabei halten wir nicht fest, ob diese Person schon einmal befragt wurde. Es kann also vorkommen, wenngleich es auch bei einer großen Wählerschaft entsprechend unwahrscheinlich ist, dass dieselbe Person mehrmals befragt wird. Die Anzahl der Befragten, die angeben, die Partei A zu wählen, ist vom Zufall abhängig und deshalb eine Zufallsvariable. Da die befragten Personen zufällig und unabhängig voneinander ausgewählt werden, ist die Zufallsvariable binomialverteilt mit den Parametern und dem unbekannten Parameter . Nehmen wir an, in der Umfrage haben Befragte angegeben, die Partei A zu wählen. Man berechnet einen Schätzwert von als:




- .

Man nennt dies eine Punktschätzung, weil nur ein Wert als Schätzung von berechnet wird.
Der wahre Wert des relativen Anteils kann sowohl kleiner als auch größer als der Punktschätzwert sein. Mit Sicherheit gilt nur, dass jeden Wert zwischen 0 und 1 annehmen kann. Wünschenswert wäre ein Konfidenzintervall für . Beim vielfachen Wiederholen des Verfahrens sollen die berechneten Konfidenzintervalle in den „meisten Fällen“ den Parameter enthalten. Wie oft das der Fall sein soll, wird mittels der Vertrauenswahrscheinlichkeit (oder auch Konfidenzniveau) ausgedrückt. Das berechnete Intervall wird Konfidenzintervall (oder Vertrauensbereich) genannt. Oft wird gleich 95 % gewählt. Das bedeutet, dass bei Wiederholung des Verfahrens für 95 % aller Stichproben die Aussage richtig ist.
![{\displaystyle [p_{u},p_{o}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98424575123fedcd74aa88dd786da520ec467732)
![{\displaystyle p\in [p_{u},p_{o}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9fd1fbffb73b85cc8badc3c9ce5aca760ecdf705)
Wald-Intervall: Einfache Approximation durch die Normalverteilung
[Bearbeiten | Quelltext bearbeiten]Gegeben sei die binomialverteilte Zahl der Erfolge , deren Mittelwert und Varianz sind. Bei der Schätzung des Parameters ersetzt man den Erwartungswert durch die Zahl der Erfolge in der Stichprobe (der Größe n):




- .

Entsprechend folgt der Standardfehler

Systematisch kann dieses Ergebnis auch durch den Standardfehlers des Maximum-Likelihood-Schätzers

erhalten werden, wobei die Loglikelihood-Funktion ist, siehe Konstruktion des Wald-Konfidenzintervalls[2].


Daraus folgt die oft verwendete folgende Näherungsformel für die Grenzen des Konfidenzintervalls (welches auch als Standard-Intervall oder Wald-Intervall bezeichnet wird):[3]
- ,


wobei eine Konstante ist, die vom Irrtumsniveau abhängt:

- ,

wobei das Irrtumsniveau und die Quantilfunktion der Standardnormalverteilung, also die Umkehrfunktion ihrer Verteilungsfunktion bezeichnet (z. B. für ).





Wenn diese Formel verwendet wird, sollte und sein. Trotzdem kann die Verwendung des Standard-Intervalls problematisch sein. In der Abbildung ist als Beispiel die Überdeckungswahrscheinlichkeit für und illustriert. Sie liegt oft unter dem geforderten Niveau von 0,95.


![{\displaystyle p\in [0{,}125;0{,}875]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/739ad574131150a19d3e4f5bf5349b5f9894fe15)
Ein weiterer großer Nachteil der Approximation ist, dass das untere Ende des Konfidenzintervalls für sehr kleine Erfolgswahrscheinlichkeiten empirisch nicht mögliche negative Werte überdecken kann bzw. bei sehr hohen Erfolgswahrscheinlichkeiten über 1 hinaus gehen kann.
Agresti-Coull-Intervall
[Bearbeiten | Quelltext bearbeiten]Für dieses Intervall setzt man , , und verwendet die (oben beschriebene) einfache Approximation mit diesen Parametern:




Der Mittelpunkt des Intervalls ist identisch zu dem des Wilson-Intervalls und das Intervall ist nie kürzer als ein Wilson-Intervall.[4]
Falls γ = 0,95, dann ist und man bekommt eine einfache Regel: , und .




Wilson-Intervall
[Bearbeiten | Quelltext bearbeiten]Dieses Intervall wurde 1927 von Edwin Bidwell Wilson vorgeschlagen und ist genauer als die einfache Approximation durch die Normalverteilung. Es gilt, mit dem gleichen wie im Abschnitt über die Approximation durch die Normalverteilung,

Offenbar konvergieren die Intervallgrenzen für große gegen die Grenzen des Standard-Intervalls (da und mit wachsendem gegen Null gehen).


Durch Umformen erhält man die bei Brown/Cai/DasGupta auf Seite 107 angegebene Formel (4):

Die bei Henze auf Seite 228 angegebene Formel unterscheidet sich davon noch durch eine Stetigkeitskorrektur (von +0,5 oder −0,5 angewandt auf ).
Clopper-Pearson-Intervall
[Bearbeiten | Quelltext bearbeiten]


Von C. Clopper und Egon Pearson (1934) stammt das folgende exakte Verfahren, um die untere Grenze und die obere Grenze zu bestimmen.[5] Es sei, wie bisher, die Größe der Stichprobe, die Anzahl der Erfolge und das Konfidenzniveau sei 95 %.


Die obere Grenze bestimmt man aus und die untere Grenze aus , siehe Abbildung. Die untere Grenze lässt sich für mit dieser Formel nicht angeben.



Erläuterung: Wenn die Wahrscheinlichkeit, höchstens Erfolge zu erzielen, für einen Anteilswert die Grenze 0,025 unterschreitet, so kann bei einer Irrtumswahrscheinlichkeit von maximal 2,5 % ausgeschlossen werden, dass der gesuchte Anteilswert ist. Somit ist po der größte Wert von , bei dem beim gegebenen Konfidenzniveau noch angenommen werden kann, dass k oder weniger Erfolge auftreten. Für größere Werte von erscheint dies zu unwahrscheinlich.
Für die untere Grenze gilt entsprechend: ist der kleinste Wert von , bei dem noch angenommen wird, dass oder mehr Erfolge auftreten können. Für kleinere Werte von erscheint dies zu unwahrscheinlich, wobei auch hier die Irrtumswahrscheinlichkeit maximal 2,5 % beträgt. Somit liegt man in mindestens 95 % aller Fälle mit der Aussage „ und “ richtig.


Praktische Berechnung
[Bearbeiten | Quelltext bearbeiten]Die beiden Werte pu, po lassen sich mit der verallgemeinerten inversen Verteilungsfunktion der Betaverteilung berechnen; dafür eignet sich beispielsweise die Funktion BETAINV[6] gängiger Tabellenkalkulationsprogramme wie Excel oder LibreOffice Calc, in Python kann die Funktion scipy.stats.beta.ppf[7] benutzt werden. Die Funktion gibt das Quantil der angegebenen Betaverteilung zurück und man erhält aufgrund des Zusammenhangs der Binomial- und Betaverteilung für die Auflösung der Gleichung :

- . Im Folgenden bezeichnen wir wie bisher das Konfidenzniveau mit , außerdem sei .

Im Beispiel mit sowie Konfidenzniveau von 95 % erhält man so für die untere Grenze des Konfidenzintervalls:

- P(X ≥ 20) = 0,025
- P(X ≤ 19) = 0,975

und für die obere Grenze des Konfidenzintervalls:


Die Berechnung der Grenzen des Konfidenzintervalls mit scipy.stats.beta.ppf erfolgt analog:
from scipy.stats import beta
k = 20
n = 400
alpha = 0.05
p_u, p_o = beta.ppf([alpha/2, 1 - alpha/2], [k, k + 1], [n - k + 1, n - k])
Erläuterung des Ergebnisses in Worten: In der Stichprobe von 400 befragten Personen gaben 20 Personen an, Partei A zu wählen. Damit lässt sich bei 95-prozentiger Konfidenz der Stimmanteil der Partei A in der gesamten Bevölkerung mit 3,1 % – 7,6 % abschätzen.
Die Methode ist in der folgenden Tabelle zusammengefasst:
| allgemeiner Fall | Sonderfall | |
| untere Grenze | pu = BETAINV(α/2;k;n-k+1) | pu=0 für k=0 |
| obere Grenze | po = BETAINV(1-α/2;k+1;n-k) | po=1 für k=n |
Analyse der Überdeckungswahrscheinlichkeit
[Bearbeiten | Quelltext bearbeiten]Ist das Konfidenzintervall zu Erfolgen, so verlangt man laut Definition, dass für alle die Überdeckungswahrscheinlichkeit größer oder gleich ; ist. Bei stetigen Verteilungen lassen sich Konfidenzintervalle finden, so dass hier Gleichheit vorliegt (also statt ). Dies ist für die diskrete Binomialverteilung nicht möglich. In folgender Abbildung ist die Überdeckungswahrscheinlichkeit in Abhängigkeit von dargestellt. Das Clopper-Pearson-Intervall wird übrigens deshalb exakt genannt, weil es eine Überdeckungswahrscheinlichkeit sicherstellt, die für alle tatsächlich größer oder gleich dem geforderten Konfidenzniveau ist. Für die anderen oben besprochenen Approximationen ist das nicht der Fall: hier gibt es oft Überdeckungswahrscheinlichkeiten, die kleiner sind als das geforderte Niveau!




Die Überdeckungswahrscheinlichkeit berechnet man in Abhängigkeit von und als Erwartungswert der Indikatorfunktion , wobei der Träger der Indikatorfunktion von der Zahl der Erfolge abhängt, die Binomialverteilt mit sind:
![{\displaystyle \mathbf {1} _{[p_{u}(k),p_{o}(k)]}(p)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/461ee82793c327ca9336cd82c618e295470046dd)

- .
![{\displaystyle P_{p}(k\in \{0,\ldots ,n\}:p\in C(k))=\sum _{k=0}^{n}B(k|p,n)\cdot \mathbf {1} _{[p_{u}(k),p_{o}(k)]}(p)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2dd1b4be99164ad9759dda42e49fa39f5aab2ab1)
Die Indikatorfunktion nimmt den Wert 1 an, wenn im Konfidenzintervall liegt, und sonst den Wert 0. Für setzt man und für setzt man .



Diskussion der Vor- und Nachteile der Verfahren
[Bearbeiten | Quelltext bearbeiten]Die beschriebenen Methoden werden in dem grundlegenden Artikel von Brown/Cai/DasGupta[8] verglichen. Dort wird das Standard-Intervall auch Wald-Intervall genannt (nach Abraham Wald). Brown/Cai/DasGupta empfehlen drei Intervall-Methoden: für größere Fallzahlen das Agresti-Coull-Intervall und für kleinere Fallzahlen das Wilson-Intervall und das Jeffreys-Intervall, welches wir hier nicht besprochen haben.[9] Für einen graphischen Vergleich der oberen und unteren Grenzen für die vier Methoden siehe auch die Abbildung am Anfang dieser Seite und die folgenden vier Abbildungen, welche eine Überdeckungswahrscheinlichkeit kleiner rot einfärben, eine Überdeckungswahrscheinlichkeit größer gleich in grün:

-
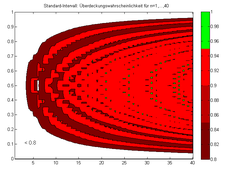 Beim Standard-Intervall liegt die Überdeckungswahrscheinlichkeit für n=1,…,40 fast immer unter dem geforderten Konfidenzniveau.
Beim Standard-Intervall liegt die Überdeckungswahrscheinlichkeit für n=1,…,40 fast immer unter dem geforderten Konfidenzniveau. -
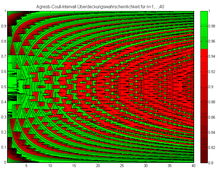 Die Überdeckungswahrscheinlichkeit für das Agresti-Coull-Intervall für n=1,…,40.
Die Überdeckungswahrscheinlichkeit für das Agresti-Coull-Intervall für n=1,…,40. -
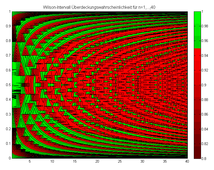 Die Überdeckungswahrscheinlichkeit für das Wilson-Intervall für n=1,…,40.
Die Überdeckungswahrscheinlichkeit für das Wilson-Intervall für n=1,…,40. -
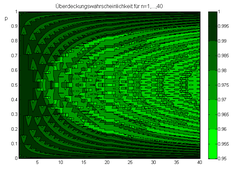 Für n=1,…,40 ist hier die Überdeckungswahrscheinlichkeit für das Clopper-Pearson-Intervall aufgetragen. Sie ist stets größer als γ=0,95.
Für n=1,…,40 ist hier die Überdeckungswahrscheinlichkeit für das Clopper-Pearson-Intervall aufgetragen. Sie ist stets größer als γ=0,95.




Literatur
[Bearbeiten | Quelltext bearbeiten]- Alan Agresti, Brent A. Coull: Approximate is better than 'exact' for interval estimation of binomial proportions. In: The American Statistician. 52, 1998, S. 119–126. doi:10.1080/00031305.1998.10480550 JSTOR:2685469
- Lawrence D. Brown, T. Tony Cai, Anirban DasGupta: Interval Estimation for a Binomial Proportion. In: Statistical Science. 16 (2), 2001, S. 101–133. doi:10.1214/ss/1009213286 JSTOR:2676784
- C. Clopper, E. S. Pearson: The use of confidence or fiducial limits illustrated in the case of the binomial. In: Biometrika. 26, 1934, S. 404–413. doi:10.1093/biomet/26.4.404 JSTOR:2331986
- T. D. Ross: Accurate confidence intervals for binomial proportion and Poisson rate estimation. In: Computers in Biology and Medicine. 33, 2003, S. 509–531. doi:10.1016/S0010-4825(03)00019-2
- E. B. Wilson: Probable inference, the law of succession, and statistical inference. In: Journal of the American Statistical Association. 22, 1927, S. 209–212. doi:10.1080/01621459.1927.10502953 JSTOR:2276774
- Norbert Henze: Stochastik für Einsteiger: Eine Einführung in die faszinierende Welt des Zufalls. 8. Auflage. Vieweg+Teubner Verlag, 2010, ISBN 978-3-8348-0815-8, doi:10.1007/978-3-8348-9351-2.
- Ulrich Krengel: Einführung in die Wahrscheinlichkeitstheorie und Statistik. 8. Auflage. Vieweg, 2005.
- Horst Rinne: Taschenbuch der Statistik. Harri Deutsch, 2003.
Weblinks
[Bearbeiten | Quelltext bearbeiten]- Vorsicht bei der sigma-Regel aus: Praxis der Mathematik, Heft 67 (2016) S. 44–47
Einzelnachweise
[Bearbeiten | Quelltext bearbeiten]- ↑ Die wichtigsten Methoden werden in dem grundlegenden Artikel von Brown/Cai/DasGupta verglichen. Außer den hier angegebenen wird dort noch z. B. das Jeffreys-Intervall besprochen.
- ↑ Supplement: Loglikelihood and Confidence Intervals. Abgerufen am 14. Juli 2021.
- ↑ Siehe hierfür und auch für die Clopper-Pearson- und Wilson-Intervalle Seite 459 des Taschenbuch der Statistik von Horst Rinne.
- ↑ Siehe Brown/Cai/DasGupta, S. 108
- ↑ Siehe Krengel, Kapitel 4.7, Abschnitt Konfidenzintervalle für die Erfolgswahrscheinlichkeit
- ↑ BETAINV-Funktion. microsoft.com, abgerufen am 1. August 2021.
- ↑ scipy.stats.beta. docs.scipy.org, abgerufen am 1. August 2021 (englisch).
- ↑ Lawrence D. Brown, T. Tony Cai, Anirban DasGupta: Interval Estimation for a Binomial Proportion. In: Statistical Science. Band 16, Nr. 2, 1. Mai 2001, ISSN 0883-4237, doi:10.1214/ss/1009213286.
- ↑ Ihr Artikel wird ergänzt durch fünf Kommentare von (1) Alan Agresti und Brent A. Coull (2) George Casella (3) Chris Corcoran und Cyrus Mehta (4) Malay Ghosh (5) Thomas J. Santner und abgeschlossen durch eine Erwiderung von Brown/Cai/DasGupta.