Organic Computing
Organic Computing bezeichnet eine interdisziplinäre Forschungsinitiative mit dem explanatorischen Anliegen, ein besseres Verständnis organischer Strukturen zu gewinnen und dem Entwicklungsziel einer organisch strukturierten Informationstechnologie. Die Forschungsinitiative nimmt Bezug auf das biologische Paradigma selbstorganisierter Informationsverarbeitung in organischen Systemen. Biologische Organismen zeigen spezifische phänomenale Merkmale, sogenannte Selbst-x-Eigenschaften, die als Qualitätsmerkmale einer organisch strukturierten Informationstechnologie angeführt werden. Die Verwirklichung der erwünschten Qualitätsmerkmale soll auf dem Konzept der Selbstorganisation basieren. Diese grundlegende methodologische Positionierung impliziert insbesondere eine Abkehr von der algorithmisch organisierten Informationstechnologie.[1][2]
Unter anderem werden – motiviert durch die Herausforderungen für die Informatik bezüglich der Gestaltung technischer Systeme, die ab etwa 2015 präsent sein werden – Antworten auf die Probleme der zu erwartenden Technologieentwicklungen erarbeitet. Die fortschreitende Miniaturisierung und die Steigerung der Leistungsfähigkeit mikro- und nanoelektronischer Systeme führen dazu, dass zukünftig eine Vielzahl intelligenter Systeme existieren wird, die in dynamisch veränderlichen Einsatzumgebungen ihre Dienste erbringen. Über unterschiedlichste Kommunikationssysteme werden Informationen untereinander ausgetauscht, es entstehen zwangsläufig Netzwerke intelligenter Systeme, deren Verhalten nicht vollständig vorhersehbar sein wird. Die einzelnen Komponenten müssen somit in der Lage sein, auch in unvorhergesehenen Situationen sinnvoll zu reagieren, d. h. technische Systeme werden sich in ihrem Verhalten aufeinander und mit der Umgebung abstimmen können und müssen – sie passen sich an und sie organisieren sich selbst.
Selbst-x-Eigenschaften[Bearbeiten | Quelltext bearbeiten]
Selbstorganisation stellt an sich kein Qualitätsmerkmal dar, weil eine selbstorganisierte Systemkonfiguration nicht notwendigerweise der technischen Zielsetzung entspricht. Unkontrollierte Selbstorganisationsprozesse können mitunter vollkommen dramatische Folgen haben[3]. Selbstorganisierte Systeme sollen darum beherrschbar bleiben. Sie sollen keine Verhaltensweisen entwickeln, die der gewünschten Funktionalität und den aktuellen Anforderungen insbesondere menschlicher Nutzer zuwiderlaufen. Die Frage bezüglich der Technologie der Zukunft ist deshalb nicht, ob selbstorganisierte Systeme entstehen, sondern wie wir diese gestalten werden.
Benötigt werden Systeme, die sich durch eine ausreichende Zahl von Freiheitsgraden an unterschiedliche Einsatzbedingungen und funktionale Anforderungen anpassen können, die Fehlverhalten von Komponenten durch geeignete Maßnahmen ausgleichen, dabei insbesondere die Bedürfnisse menschlicher Nutzer berücksichtigen und insgesamt den Menschen in seinen Lebensumständen auf vielfältige Weise vertrauenswürdig unterstützen. Es werden Systemarchitekturen benötigt, die sich insbesondere durch Robustheit und Flexibilität auszeichnen. Wegen des lebensähnlichen Verhaltens solcher Systeme werden sie organisch genannt. Die zukünftigen organischen Informatiksysteme sollen eine Reihe sogenannter Selbst-x-Eigenschaften aufweisen,[4][5][6][7] sie seien insbesondere
- selbst konfigurierend,
- selbst optimierend,
- selbst heilend,
- selbst schützend und
- selbst erklärend.
Nach Vorstellung der Vision des Organic Computing in einem Positionspapier der GI und ITG/VDE[8] gab die Einrichtung des DFG-Schwerpunktprogramms 1183 Organic Computing dieser neuen Forschungsrichtung wesentlichen Auftrieb. In derzeit 18 Forschungsprojekten werden bis zum Jahr 2011 Eigenschaften selbst organisierender Systeme grundlegend untersucht, geeignete Systemarchitekturen entworfen und Werkzeuge entwickelt, die den Entwurf und das Management dieser Systeme vielfältig unterstützen.
Das Gebiet des Organic Computing hat starke Bezüge zur Autonomic Computing Initiative von IBM[9], die sich allerdings auf die Beherrschung der Komplexität großer Serverarchitekturen durch Erzeugung von Selbst-x-Eigenschaften konzentriert. Organic Computing beachtet jedoch insbesondere das durch lokale Interaktion entstehende Verhalten des Gesamtsystems, in dem nicht vorhergesehene globale Effekte auftreten können. Da nicht jedes selbst organisierend entstehende (auch emergent genannte) Verhalten gewünscht wird, strebt Organic Computing nach einer Form von gesteuerter Selbstorganisation, wie sie unter anderem durch die generische Observer/Controller-Architektur[10] erzielt wird.
Observer/Controller-Architektur[Bearbeiten | Quelltext bearbeiten]
Im Bereich organischer, autonomer und autonom-naher Systeme gibt es neben der Observer/Controller-Architektur eine Reihe weiterer Architekturansätze zur Unterstützung selbst organisierenden, adaptiven Verhaltens. Zu nennen sind hier insbesondere
- der MAPE-Zyklus, der mit Monitor, Analyze, Plan und Execute die wesentlichen Arbeitsschritte eines Autonomic Element beschreibt und damit ein zentrales Konzept des Autonomic Computing ist[9],
- die vom DFG-Sonderforschungsbereich 614 entwickelten Operator/Controller-Module[11], die ihren Einsatzschwerpunkt bei selbst optimierenden Systemen des Maschinenbaus haben,
- die im Rahmen des Projekts Organic Fault-Tolerant Control Architecture for Robotic Applications konzipierten Organic Control Units (OCU), die ein selbst organisiertes Verhalten 6-beiniger Laufroboter ermöglichen[12],
- die SPA-Architektur (Sense, Plan und Act)[13] aus der Robotik oder die 3-Ebenenarchitektur (component control, change management und goal management) aus dem Software Engineering für adaptive Systeme[14],
- agentenbasierte Ansätze, wie sie zum Beispiel im Roboterfußball (z. B.[15]) oder in selbst organisierenden Fabrikanlagen (z. B.[16]) zum Einsatz kommen, sowie
- autonome System-On-Chip-Architekturen (z. B.[17]).
In der Observer/Controller-Architektur sind die wesentlichen Komponenten dieser Architekturansätze zu einem generischen Konzept zusammengeführt, in dem insbesondere auch die Aspekte des maschinellen Lernens berücksichtigt werden.
- Verschiedene Observer/Controller-Architekturen
-
 Zentral
Zentral -
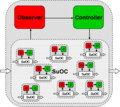 Mehrschichtig
Mehrschichtig -
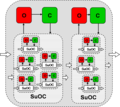 Hierarchisch
Hierarchisch -
 Verteilt
Verteilt




Die Observer/Controller-Architektur beobachtet, analysiert und bewertet bezüglich vorgegebener Zielkriterien in einer Art Regelkreis das Verhalten der zu überwachenden Systeme. Dies führt zur Auswahl geeigneter Maßnahmen, um das zukünftige Verhalten in der gewünschten Richtung zu beeinflussen. Die Architektur besteht aus einem Netzwerk autonomer Einheiten (genannt Produktivsystem), ergänzt durch jeweils eine oder mehrere Observer- und Controller-Einheiten. Für den Observer muss eine angemessene Methodik entwickelt werden, um das (globale) Systemverhalten zu beobachten und hinsichtlich des Auftretens von Emergenzeffekten zu analysieren und zu bewerten. Ein auf Shannons Entropiedefinition basierendes Verfahren zur Quantifizierung von Emergenz wird in[18][19] vorgeschlagen. Der Controller soll aufgrund der Ergebnisse des Observers entscheiden, in welcher Form das Produktivsystem beeinflusst werden muss, um ein kontrolliertes selbst organisiertes globales Verhalten innerhalb der Grenzen und Ziele zu ermöglichen, die von einer externen Einheit (der Umgebung) vorgegeben sind. Der Controller soll somit in der Lage sein, sein Verhalten lernend zu verbessern, d. h. insbesondere aufgrund von Erfahrungen bezüglich der Wirkung früherer Aktionen sein Verhalten anzupassen. Für mehr Informationen zum generischen Framework sei auf[10] verwiesen.
Robustheit und Flexibilität[Bearbeiten | Quelltext bearbeiten]
Neben der Quantifizierung und Beherrschbarkeit von emergentem Verhalten gilt die Forderung nach Robustheit und Adaptivität eines organischen Systems als eine der wesentlichen Herausforderungen: Wie muss ein System gestaltet werden, damit es sich in seiner Funktionalität an Veränderungen der Einsatzumgebung anpassen und gleichzeitig robust reagieren kann, d. h. seine Funktionalität trotz Veränderungen in Umgebungsparametern weiterhin erfüllt? Wie können Systemeigenschaften wie Robustheit, Flexibilität, Autonomie und Selbstorganisation quantitativ bestimmt werden? Ansätze für eine verstärkt quantitative Betrachtung finden sich u. a. in [20].
Bis zur Realisierung der in der Vision des Organic Computing formulierten Systemanforderungen ist es noch ein weiter Weg. Allerdings sind im DFG-Schwerpunktprogramm 1183 Organic Computing bereits wichtige Konzepte entwickelt und Teilergebnisse erzielt worden. Wichtig ist die Ergänzung dieses grundlagenorientierten Forschungsprogramms durch weitere, mehr anwendungsorientierte Forschungsprojekte, um die im Schwerpunktprogramm gewonnenen theoretischen und methodischen Erkenntnisse in konkreten technischen Systemen zu erproben und weiterzuentwickeln.
Aktuelle Forschung[Bearbeiten | Quelltext bearbeiten]
Erste Schritte in Richtung organischer, selbst organisierender und adaptiver Systeme werden im DFG Schwerpunktprogramm 1183 Organic Computing unternommen.[3] Dabei werden eine Vielzahl von Fragestellungen betrachtet, die neben anderen Aspekten folgende Schwerpunkte umfassen: Adaptivität, Rekonfigurierbarkeit, Emergenz neuer Systemeigenschaften und Selbstorganisation in technischen Systemen.
Literatur[Bearbeiten | Quelltext bearbeiten]
- Würtz, Rolf P. (Editor): Organic Computing (Understanding Complex Systems). Springer, 2008. ISBN 978-3642096426.
- Sinsel, Alexander: Organic Computing (als Konzept zur Steuerung interagierender Prozesse in verteilten Systemen). Optimus Wissenschaftsverlag, Göttingen, März 2011. ISBN 978-3941274679.
- Christian Müller-Schloer, Hartmut Schmeck, Theo Ungerer (Editor): Organic Computing - A Paradigm Shift for Complex Systems. Springer, 2011. ISBN 978-3-0348-0129-4
Weblinks[Bearbeiten | Quelltext bearbeiten]
- Organic Computing Initiative
- VDE/ITG/GI-Positionspapier Organic Computing (PDF; 140 kB)
- DFG Schwerpunktprogramms 1183 Organic Computing
- FAQ zu selbst organisierenden Systemen (englisch)
Einzelnachweise[Bearbeiten | Quelltext bearbeiten]
- ↑ Kapitel 2.1 (PDF; 377 kB) aus Sinsel, Alexander: Organic Computing (als Konzept zur Steuerung interagierender Prozesse in verteilten Systemen). Optimus Wissenschaftsverlag, Göttingen, März 2011. ISBN 978-3941274679.
- ↑ Von der Malsburg, Christoph: The Challenge of Organic Computing. Memorandum, 1999 ( des vom 2. Juli 2010 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis. (PDF; 38 kB).
- ↑ a b DFG Schwerpunktprogramms 1183 Organic Computing
- ↑ H. Schmeck. Organic Computing. Künstliche Intelligenz, 3:68–69, 2005.
- ↑ C. Müller-Schloer, C. von der Malsburg und R. P. Würtz. Organic Computing, Aktuelles Schlagwort in Informatik Spektrum, Seiten 332–336, 2004.
- ↑ C. Müller-Schloer. Organic Computing – On the Feasibility of Controlled Emergence. In Proceedings of the 2nd IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis (CODES + ISSS 2004), Seiten 2–5. ACM Press, 2004.
- ↑ H. Schmeck. Organic Computing – A new vision for distributed embedded systems. In Proceedings of the 8th IEEE International Symposium on Object-Oriented Real-Time Distributed Computing (ISORC 2005), Seiten 201–203. IEEE Computer Society, 2005.
- ↑ Positionspapier von GI und ITG/VDE (PDF; 140 kB)
- ↑ a b J. O. Kephart und D. M. Chess. The vision of autonomic computing. IEEE Computer, 1, Seiten 41–50, 2003.
- ↑ a b U. Richter, M. Mnif, J. Branke, C. Müller-Schloer und H. Schmeck. Towards a generic observer/controller architecture for Organic Computing. In C. Hochberger and R. Liskowsky, editors, INFORMATIK 2006 – Informatik für Menschen!, volume P-93 of GI-Edition – Lecture Notes in Informatics (LNI), Seiten 112–119. Köllen Verlag, 2006.
- ↑ O. Oberschelp, T. Hestermeyer, B. Kleinjohann und L. Kleinjohann. Design of self-optimizing agent-based controllers. In CfP Workshop 2002 – Agent-Based Simulation 3, 2002.
- ↑ F. Mösch, M. Litza, A. El Sayed Auf, E. Maehle, K. E. Großpietsch und W. Brockmann. ORCA – Towards an Organic Robotic Control Architecture. In H. De Meer und J. P. G. Sterbenz, editors, Proceedings of the 1st International Workshop on Self-Organizing Systems (IWSOS 2006), volume 4124 of Lecture Notes in Computer Science, Seiten 251–253, Berlin/Heidelberg, Germany, September 2006. Springer.
- ↑ S. Dobson, S. Denazis, Fernndez, Antonio, D. Gati, E. Gelenbe, Massacci, P. Nixon, F. Saffre, N. Schmidt und F. Zambonelli. A survey of autonomic communications. ACM Trans. Auton. Adapt. Syst., 1, Seiten 223–259. 2006.
- ↑ E. Gat. Three-layer Architectures. Artificial Intelligence and Mobile Robots, MIT/AAAI Press, 1997.
- ↑ M. Riedmiller, T. Gabel, R. Hafner, S. Lange und M. Lauer. Die Brainstormers: Entwurfsprinzipien lernfähiger autonomer Roboter. Informatik-Spektrum, 29(3):175–190, 2006.
- ↑ H. Van Dyke Parunak. What can agents do in industry, and why? In Cooperative information agents: 2nd International workshop, 1998.
- ↑ A. Bouajila, J. Zeppenfeld, W. Stechele, A. Herkersdorf, A. Bernauer, O. Bringmann und W. Rosenstiel. Organic computing at the system on chip level. In Proceedings of the IFIP International Conference on Very Large Scale Integration of System on Chip (VLSI-SoC 2006), 2006.
- ↑ M. Mnif und C. Müller-Schloer. Quantitative Emergence. In Proceedings of the 2006 IEEE Mountain Workshop on Adaptive and Learning Systems (IEEE SMCals 2006), Seiten 78–84, 2006.
- ↑ C. Müller-Schloer und B. Sick. Emergence in Organic Computing Systems: Discussion of a Contro-versial Concept. In Proceedings of 3rd International Conference on Autonomic and Trusted Computing (ATC 2006), volume 4158 of Lecture Notes in Computer Science, Seiten 1–16, 2006. Springer.
- ↑ E. Cakar, M. Mnif, C. Müller-Schloer, U. Richter und H. Schmeck. Towards a quantitative notion of self-organisation. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation (CEC 2007), Seiten 4222–4229, 2007.