Anaphraseus
| Anaphraseus
| |
|---|---|
 Anaphraseus 2.04.98b unter macOS | |
| Basisdaten
| |
| Entwickler | Oleg Tsygani, Dmitri Gabinski und Sergei Medvedev |
| Aktuelle Version | 2.08 (23. Dezember 2019) |
| Betriebssystem | Windows, Linux, Mac OS X, Solaris, FreeBSD und andere Unix-Varianten |
| Programmiersprache | StarOffice Basic |
| Kategorie | Computerunterstützte Übersetzung (CAT) |
| Lizenz | GPL (Freie Software) |
| deutschsprachig | ja |
| anaphraseus.sf.net | |
Anaphraseus ist ein Programm zur computerunterstützten Übersetzung (CAT) in Form einer freien Erweiterung für OpenOffice.org Writer. Es wurde weitgehend von Wordfast, einem proprietären CAT-Programm für Microsoft Word, inspiriert und besteht aus einer Sammlung von in StarOffice Basic geschriebenen Makros. Anaphraseus wird seit Oktober 2007 von einer Gruppe unabhängiger Übersetzer und Programmierer unter der GNU-GPL-Lizenz entwickelt.
Funktionsweise[Bearbeiten | Quelltext bearbeiten]
Der Benutzer öffnet das zu übersetzende Dokument in OpenOffice.org Writer und wählt den Übersetzungsspeicher (engl. translation memory, TM) aus, den er verwenden möchte. Steht ihm kein TM zur Verfügung, kann er ein neues anlegen. Das von der Software verwendete TM-Dateiformat ist das Wordfast-Format. Es ist ebenfalls möglich, ein TM im standardisierten TMX-Format zu importieren. Allerdings kann das Importieren auf diese Weise relativ viel Zeit in Anspruch nehmen: Um diesen Vorgang zu erleichtern, empfiehlt es sich, auf die freie Konvertierungssoftware Okapi Olifant zurückzugreifen. Darüber hinaus bietet Anaphraseus die Möglichkeit, ein oder mehrere Glossare (Wortlisten, terminologische Sammlung) einzubinden.
Der Übersetzungsvorgang verläuft linear von einem Segment (meist einem Satz) zum nächsten. Wird ein neues Segment geöffnet, unterbreitet die Software dem Benutzer einen Übersetzungsvorschlag: die im TM gespeicherte Übersetzungseinheit mit dem höchsten Ähnlichkeitsgrad zum gerade geöffneten Segment. Es steht dem Benutzer frei, diesen Übersetzungsvorschlag anzunehmen, abzulehnen oder anzupassen. Parallel dazu schlägt die Software die im gerade geöffneten Segment befindlichen Termini in dem/den vorhandenen Glossar(en) automatisch nach. Nachdem die Übersetzung des Segments abgeschlossen ist (beispielsweise durch Navigieren zum nächsten Segment), wird der vom Benutzer eingegebene Text automatisch im TM gespeichert und das Segment in der Ausgangssprache wird in den Hintergrund gestellt.
Ist die Übersetzung des Dokuments abgeschlossen, verfügt der Benutzer über eine zweisprachige Datei: Die Ausgangssegmente befinden sich im Hinter-, die Zielsegmente im Vordergrund (ähnlich wie nach einer Verwendung von Wordfast oder Trados Translator’s Workbench). Der letzte Schritt ist das «clean-up» (Entfernen der Ausgangssegmente aus dem Dokument), der durch Anklicken des entsprechenden Menüpunkts durchgeführt wird. Den um neue Segmente «erweiterten» Übersetzungsspeicher kann der Benutzer selbstverständlich für weitere Projekte einsetzen.
Übersicht über die Funktionalitäten[Bearbeiten | Quelltext bearbeiten]
Bereits implementierte Funktionalitäten[Bearbeiten | Quelltext bearbeiten]
- Übersetzungsspeicher
- Exakte und ungenaue Treffer (Exact & fuzzy matches)
- Glossare
Geplante Funktionalitäten[Bearbeiten | Quelltext bearbeiten]
- Suche innerhalb des TM (Konkordanzsuche)
- Analyse des Ausgangs- und Zieltextmaterials
- Fusionieren von TMs
Screenshots[Bearbeiten | Quelltext bearbeiten]
-
 Dialogfenster zum Konfigurieren des TM
Dialogfenster zum Konfigurieren des TM -
 Dialogfenster zum Verwalten der TM-Attribute
Dialogfenster zum Verwalten der TM-Attribute -
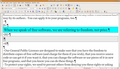 Arbeitsumgebung in OpenOffice.org Writer
Arbeitsumgebung in OpenOffice.org Writer



Literatur[Bearbeiten | Quelltext bearbeiten]
- Oleg Tsygany: „Anaphraseus: translators' workhorse“. Panace@. Vol. 10, No. 29, S. 58–60: http://www.tremedica.org/panacea/IndiceGeneral/n29_tribuna-Tsygany.pdf (en) (Permalink (Seite nicht mehr abrufbar, festgestellt im Mai 2023. Suche in Webarchiven) Info: Der Link wurde automatisch als defekt markiert. Bitte prüfe den Link gemäß Anleitung und entferne dann diesen Hinweis. (englisch))