Um einen Abschnitt dieser Seite zu verlinken, klicke im Inhaltsverzeichnis auf den Abschnitt und kopiere dann Seitenname und Abschnittsüberschrift aus der Adresszeile deines Browsers, beispielsweise
[[Diskussion:Digitalkamera/Archiv#Thema 1]]
oder als Weblink zur Verlinkung außerhalb der Wikipedia
Versionen 4.3.2004 Crissov:Kaufberatung gehört nicht in die Wikipedia...diese Kürzung finde ich bischen zu radikal, zumindest die Tabelle über den Preisverfall hätte man drinlassen können. Vielleicht ist eine Kaufberatung nicht im Sinne einer Enzyklopädie, aber das Schöne an Wikipedia ist ja, dass man auch mal über den Tellerrand gucken kann, und es gibt bestimmt viele Einsteiger, die sich hier über eine kleine Beratung freuen. Runghold 15:58, 4. Mär 2004 (CET)
Änderung 9.März.2004 Unterschrift zum Bild: Diese Kamera hat es mit 100%er Sicherheit nicht schon 1982 gegeben. Es handelt sich übrigens um meine erste Digikamera, und die habe ich ca. 1999/2000 gekauft. Bitte nochmal genau recherchieren.Runghold 00:09, 10. Mär 2004 (CET)
Bildtransfer
Letzter Kommentar: vor 16 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
Ein Aspekt, der in dem Artikel total fehlt ist die Übertragung der Bilder. Das ist ein Thema, das man v.a. als Linux-User interessant findet, da hier keine Software mitgeliefert wird. Zum einen wird alles unterstützt, das das Picture Transfer Protokoll (PTP) unterstützt - man kann aber auch Kameras mit USB-Speichermedium einbinden. Aber mit PTP geht es deutlich einfacher. Interessant wäre auch was zu en:PictBridge(nicht signierter Beitrag von217.186.154.234 (Diskussion | Beiträge) 15:44, 29. Sep. 2004 (CEST))
Letzter Kommentar: vor 17 Jahren4 Kommentare2 Personen sind an der Diskussion beteiligt
Falls jemand weiß, warum digicams immer eine mehr oder weniger extreme verzögerung beim auslösen haben, wäre dies eine erwähnung im artikel wert. (Für mich ist dies der entscheidende grund, bisher keine angeschafft zu haben.) --Nikolaus 22:16, 8. Aug 2004 (CEST)
Der Grund ist durchaus bekannt: Im Gegensatz zu Spiegelreflex-Systemkameras verwenden die meisten Sucherkameras aus Kostengründen keine spezielle Elektronik zur Fokussierung. Statt dessen wird auch dafür ein Teil des vom Bildwandler erzeugten Signals ausgelesen und der AF erfolgt durch Kontrastauswertung. Die für solche Aufgaben speziell entwickelten Bauteile von Spiegelreflexkameras waren schon wenige Modellgenerationen nach den erste AF Modellen dem AF heutiger Kompaktdigis klar überlegen. -- Bommel 23:22, 20. Jan 2007 (CET)
Das, was Bommel beschreibt, ist die Fokussierzeit und nicht die Auslöseverzögerung. Unter dem Begriff Auslöseverzögerung versteht man die Zeit, die vom Schließen des Auslösekontaktes bis zum Beginn der Aufnahme vergeht. Die Ursache für die ärgerlich lange Auslöseverzögerung ist vermutlich Folgende. Vor der Aufnahme, während der Fotograf das Motiv anvisiert und die Kamera die Fokussierung durchführen lässt, ist der größte Teil des Bildsensors noch stromlos. Von dem Moment, in dem die Stromversorgung dieses größten Teils des Bildsensors eingeschaltet wird, bis zu dem Moment, seit dem die Stromverhältnisse im Bildsensor ausreichend konstant sind, vergeht eine gewisse Zeit, die bei den berüchtigten Billigkameras auch 500 Millisekunden lang sein kann. Bei den besten Kameras sind es immerhin noch 37 Millisekunden. -- Karsten Schulze, 2007\02\09 (nicht signierter Beitrag vonKarsten Schulze (Diskussion | Beiträge) 12:34, 9. Feb. 2007 (CET))
Der Bildsensor wird nicht teilweise eingeschaltet, bei Kameras, die den Bildsensor auch für die Sucheranzeige auslesen, mithin alle außer Spiegelreflexen, hätte man sonst auch ein teilweises Sucherbild. Ein Teil der Verzögerung wird dadurch verursacht, daß der Aufnahmesensor vor Anfertigung der eigentlichen Aufnahme von den Informationen befreit werden muß, die durch die Verwendung für den elektronischen Sucher drin stecken. -- Smial17:41, 9. Feb. 2007 (CET)
Lieber Smial. Man hat ein teilweises Sucherbild. Denn der Monitor, der auch als Sucher bezeichnet wird, weist wesentlich weniger Pixel als der Bildsensor auf. Um Strom zu sparen, werden die Pixel, die für die Sucheranzeige nicht benötigt werden, nicht mit Strom versorgt, solange es nicht nötig ist. Und bei einer Reflexkamera sind das alle Pixel. Damit wäre auch erklärbar, warum Reflexkameras einen geringeren Stromverbrauch als Kompaktkameras aufweisen. -- Karsten Schulze, 2007\02\09 (nicht signierter Beitrag vonKarsten Schulze (Diskussion | Beiträge) 18:58, 9. Feb. 2007 (CET))
Es werden nicht alle Pixel für die Sucheranzeige ausgelesen, das ist richtig. Da aber alle beleuchtet werden, muß der Sensor so oder so gelöscht werden, wie ich es oben beschrieb, völlig unabhängig davon, ob das Ding nun komplett oder in Teilen ausgelesen wird. Es ist für diesen Teil der Auslöseverzöerung also völlig unerheblich. Aber hast Du eine Quelle dafür, daß so ein Sensor sich teilweise abschalten ließe? Daß SLR weniger Strom verbrauchen, liegt genau daran, daß der Sensor nur für die eigentliche Aufnahme eingeschaltet wird (und stromfressende Anzeigen ebenfalls normalerweise abgeschaltet sind). Was nebenbei wegen geringerer Erwärmung auch zu weniger Rauschen führt. Aber beides war hier nicht das Thema. -- Smial19:08, 9. Feb. 2007 (CET)
CCD / CMOS
Meines wissens ist ein CCD ein überbegriff für alle fotoempfindlichen chips, die nach dem prinzip der ladungsverschiebung zum auslesen arbeiten (mir sind keine anderen verfahren für bildaufnahmechips bekannt). CMOS ist eine grundtechnik für die funktionsweise von halbleitern. Dann wäre CCD ein überbegriff und die unterscheidung im artikel eine falsche darstellung. Wer weiß es? --Nikolaus 22:22, 8. Aug 2004 (CEST)
Da magst du recht haben. Generell sollten CCD/CMOS in (die bereits existierenden) Artikel ausgelagert werden, die Information dort ist redundant.--Jdiemer 23:01, 18. Sep 2004 (CEST)
Bitte um Gegenlesen insbesondere in Hinblick auf die Abgrenzung von Digitalfotografie, bisher waren beide Artikel eine konfuse Mischung; ich habe beide überarbeitet, weiss aber nicht so recht, ob mir das gelungen ist. --asb 19:48, 24. Aug 2004 (CEST)
übersichtlich ist es geworden, aber diese Bemerkungen zu den Megapixeln scheinen immer wieder reinzurutschen :-( siehe Diskussion Ralf 09:06, 27. Aug 2004 (CEST)
Megapixel
Letzter Kommentar: vor 18 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
Nun steht das wieder drin... Ich bin es müde darüber zu diskutieren, vielleicht hat jemand mehr Energie? 1 MB muß nicht Spielzeug sein und 4 MB kann Müll sein. Ich kann Beispiele einer 1,3 MB Kamera bringen die problemlos auf 20x30 vergrößert werden können. Qualität wird durch Objektiv und Chip bestimmt... Ralf 09:03, 27. Aug 2004 (CEST)
Das war nie raus, ich hatte auch eigentlich nicht vor, es komplett herauszunehmen; ich habe nur versucht, allzu schräge Wertungen zu neutralisieren bzw. zu relativieren. Problematisch sind die Megapixel-Angaben m.E. weil es keinen normierten Berechnungsfaktor dafür gibt (ein Pixel entsteht aus drei CCD-Zellen, Farbwerte werden interpoliert und es gibt mehr grünempfindliche Zellen), das habe ich im Abschnitt zur Funktionsweise des CCD-Sensors angedeutet, das könnte aber ausgebaut werden, beispielsweise mit einer Zeichnung oder einem Diagramm (vgl. Sensibilisierung). Völlig bedeutungslos sind die Auflösungsangaben ja auch nicht, dazu hate ich einiges geschrieben unter Ausbelichtung.
Die Aussage, die Qualität werde durch Objektiv und Chip bestimmt, ist so m.E. nicht haltbar, es sei denn, Du fasst unter Chip die (mindestens) vier Komponenten (1) Anzahl der CCD-Zellen, (2) Bildwandlung in elektrische Signale, (3) Digitalisierung bzw. A/D-Wandlung mit Diskretisierung und Quantisierung und (4) kamerainterne Bildverarbeitung einschließlich Kompression (ich bin ja immer wieder fasziniert, wie gut meine Bilder im Rohdatenformat plötzlich sind ;) zusammen.
Problematisch ist für uns auch, dass niemand von uns die "Qualität" eines Objektivs objektiv messen kann, weil wir ja bestenfalls einen Siemensstern abfotografieren und dann die Linien abzählen können; will sagen, uns fehlt eine handhabbare Alternative, um Digitalkameras in Leistungsklassen einzuteilen. Wir müssen also im Artikel zumindest erwähnen, dass und warum die Megapixel-Anzahl zur Einteilung von Leistungsklassen durch die Industrie und Fotozeitschriften genutzt wird; dann könnten wir noch im Detail erläutern, warum das problematisch ist, vielleicht in einem speziellen Artikel Auflösung (Fotografie), der alle relevanten Faktoren zusammenfasst. --asb 11:19, 27. Aug 2004 (CEST)
Ich möchte ja keinen zu nahe Tretten, aber könnte man denn Artikel nicht etwas Kürzen und vielleicht auch wider mit Aktuellen Daten füllen.
Das Jahr 2004 ist ja schon lange um ;-). Und es wider hollen sich auch vielle sachen.
Ansonnsten Danke für denn Artikel an Alle Beteiligten. Er Hat mir schon mal ein Guten überblick über das Gebit Digicam gegeben ;-) (nicht signierter Beitrag von84.155.216.50 (Diskussion | Beiträge) 11:56, 30. Mai 2005 (CEST))
Lesenswert-Diskussion
Ein digitaler Fotoapparat, auch Digitalkamera genannt, ist ein Fotoapparat, bei dem das Aufnahmemedium Film durch einen elektronischen Bildwandler (Sensor) und ein digitales Speichermedium ersetzt wurde.
Meiner Meinung nach sollte der Artikel zum Lemma Digitalkamera verschoben werden, da dies deutlich gebräuchlicher ist als das Lemma Digitaler Fotoapparat. Gibt es Gründe, die dagegen sprechen? --Birger(Diskussion) 01:19, 8. Okt 2005 (CEST)
Bin ich auch dafür, kann es leider nicht selber machen, wenn du das machen könntest wäre super. --Benedikt Jockenhöfer 00:57, 18. Jan 2006 (CET)
Pro Eindeutig dafür. --Overclocker 20:24, 23. Jul 2006 (CEST)
Die reale Megapixel-Grenze
Letzter Kommentar: vor 17 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
Ein wichtiger Hinweis fehlt, sollte bei einer Überarbeitung eingefügt werden:
Die Auflösung wird nicht nur durch Objektiv und Chip (Megapixel) begrenzt, sondern auch durch die Bewegungsunschärfe. Für Aufnahmen OHNE Stativ (sofern nicht gerade bei gleißender Sonne im Schnee mit extrem kurzer belichtungszeit) sind i.d.R. 3 Megapixel völlig ausreichend; ruhiger kann man die Kamera nämlich schlicht nicht halten !
Was mit Digitaltechnik nur am Rande zu tun hat. -- Smial 14:50, 15. Apr 2006 (CEST)
Das mag man innerhalb einer gewissen Kameraklasse, die über eine gewisse Empfindlichkeit hinaus nicht brauchbar ist oder diese gar nicht erst anbietet, ja meinetwegen so sehen. Mit einer modernen digitalen Spiegelreflex macht man aber auch mit 10 Megapixeln bei ISO 800 noch da knackscharfe Fotos, wo man mit einer 3 Megapixel Kompaktkamera am Start entweder unscharfe oder verrauschte Fotos erntet. Ein optischer Bildstabilisator macht diesen Einwand übrigens auch schon zunichte. Bommel 23:28, 20. Jan 2007 (CET)
Ich glaube irgendwo (c't?) gelesen zu haben, dass ein "normaler Film" eine Auflösung von etwa 20 MP hat- nach der Entwicklung waren es effektiv weniger.
Die 10 MP bei Kompaktkameras sind eher Marketing mehr nicht. Laut c't 21/2006 bleiben, wg. der zu kleinen CMOS-Sensor Fläche (1/1,8" bei sage und schreibe 10 MP->pro Fotodiode noch weniger Licht, noch mehr Verstärkung, mehr Rauschen als z.B. bei 3 MP und 1/1,8") und schlechtem Objektiv nur effektiv 6 bis 7 MP übrig.
<IMHO>
Also insgesamt (bes. bei SLR) gibt es fast keine MP Grenze vom CMOS-Sensor her (Integrationsdichte, Fläche des Sensors). Die einzige Grenze sind das Objektiv und die Kosten für den Sensor (Ausbeute pro Wafer).
Ich denke, dass über 20 MP keinen Sinn mehr macht außer man möchte die toten Mücken auf der Frontscheibe, aus 1 km Entfernung aufgenommen, mal in A4 Größe sehen. ;)
</IMHO> - Appaloosa00:41, 21. Jan. 2007 (CET)
Für Diskussionen, Bashing, Flame Wars aller Art, aber auch manche sehr nützliche Information empfehle ich groupsgoorglen in d.r.f. und d.a.r.d., außerdem mit gewissen Einschränkungen dpreview. Tatsächlich hat die Megapixelmanie bei kleinen Sensoren inzwischen zu weitgehend unbrauchbaren Kompaktkameras geführt, die eigentlich nur noch den Speicherkartenherstellern nutzen. 20 MPixel können btw. je nach Anwendung durchaus sehr sinvoll sein, es gibt sogar größere Sensoren mit noch viel mehr Megapixeln. -- Smial03:36, 21. Jan. 2007 (CET)
Lichtempfindlichkeit, Bildrauschen
Letzter Kommentar: vor 17 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
Unterscheidung der Lichtempfindlichkeit zwischen Kompakt- und SLR-Kameras:
Bei SLR ist die Lichtempfindlichkeit durch die im Durchschnitt größere CCD-Chip-Fläche besser. Wodurch das Bildrauschen viel geringer ist als bei Kompaktkameras mit kleinerer Chipfläche. Selbst ein nachgeschalteter Verstärker nach dem CCD-Chip bei Kompaktkameras hilft nichts, da dieser nur das Rauschen mitverstärkt. Liege ich da Richtig mit meiner Behauptung? Wenn ja, baue ich das in den Artikel ein. - Appaloosa13:05, 13. Mai 2006 (CEST)
Nicht ganz. Das Rauschen ist stark von der Größe der einzelnen "Pixel" abhängig. ein Verstärker ist in /jeder/ Kamera nachgeschaltet, bei kleinen Pixeln muß aber mehr verstärkt werden als bei großen, um auf dieselbe Lichtempfindlichkeit zu kommen, und damit wird das Rauschen automagisch mitverstärkt. BTW: Es gibt CMOS- und CCD-Sensoren. -- Smial02:19, 14. Mai 2006 (CEST)
Leistungsklassen und Auflösung
Letzter Kommentar: vor 16 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
Der Abschnitt ist extrem POV durch wertende Einteilungen in "Profi"- und sonstige "Klassen", zumal "Profi" und nicht-Profi mit der Sensorauflösung nur eine geringe Korrelation hat. Außerdem hinken die ständigen Auflösungsvergleiche mit Kleinbildfilm stets auf beiden Beinen. -- Smial 12:07, 26. Jun 2006 (CEST)
Die Aussage, dass keine Filme der ISO-KLasse 25 mehr hergestellt werden, ist definitiv falsch. Unter dem Namen Gigabitfilm werden Analogfilme hergestellt, die u.a. als Planfilm mit einer Auflösung von 900 Linienpaaren/mm erhältlich sind. Rollfilme sind in den ISO-Klassen 40 und 32 erhältlich. (siehe gigabitfilm.de) -- Vincent Weiß (nicht signierter Beitrag von86.56.6.157 (Diskussion | Beiträge) 22:59, 3. Okt. 2007 (CEST))
Auflösung
Wie ich sehe wurde meine Änderung wieder rückgängig gemacht.
Erstmal ist es schwer die Auflösung vom Film mit Digital zu vergleichen, tut man dies jedoch dennoch, sollte man es realistisch machen und nicht theoretisch.
Die Auflösung eines Kleinbildfilmes von bis zu 20 Mio. Pixel ist eine theoretische Maximalauflösung bei einem Objektkontast 1000:1 welches nicht sehr realistisch ist.
Ich berufe mich da lieber auf Profis die wirklich mal Praxisnah getestet haben, Z.B. hier:
Auch wenn hier keine KB-Film Kamera dabei ist, Zeigt es sehr deutlich das ein 645 Fuji Velvia etwa das gleiche auflöst wie eine 16 Mio. Pixel Kamera. Auf Kleinbildformat umgerechnet sind das ca. 5-6 Mio. Pixel. Das kommt auch etwa hin mit der Theorie wenn man statt 1000:1 Kontrast 1,6:1 nimmt. Siehe Wikipedia-Artikel Auflösung (Fotografie)
Wo ist jetzt der Gegenbeweis, das ein Film 6-10 Mio. Pixel auflöst? Und der alte Ektar 25 sogar 20 Mio. Pixel? Wie könnte er, der Fuji Velvia hat etwa die gleiche Auflösung.
warst du 172.177.15.128 eben? Bei dem Revert ging es einfach darum, dass keine Quelle für die tiefgreifende Änderung der Angaben genannt war.
Wie du schreibst, ist der Vergleich der Auflösung von Film zu Sensor nicht gerade einfach. Es ist aber wahrscheinlich besser, das einfach im Artikel zu erwähnen und fundiert zu begründen, als einfach eine Zahl zu nennen. Was du oben geschrieben hast, ist doch schon ein guter Ansatz.
hm, mal eine Anregung - ich hab heute im Deutschlandfunk einen Bericht von der photokina gehört - dabei wurde erwähnt, dass Staub ein bekanntes Problem bei Digitalkameras ist, weil er ja nicht mit dem Film abtransportiert wird. Er sammelt sich wohl gerne bzw. besonders negativ auffallend auf dem Sensor. Die Hersteller entwickeln (oder haben schon) besondere Lösungen (welche, das habe ich leider vergessen), um das Problem in den Griff zu bekommen. Auf meine Kamera musste ich vor einigen Wochen verzichten, da sie mit genau dieser Diagnose in die Werkstatt des Herstellers ging. Ich wusste bis heute nicht, dass das ein so bekanntes Problem ist. Das wäre doch durchaus eine Information, die in den Artikel könnte, oder? Gruß, -- Schusch 00:27, 29. Sep 2006 (CEST)
Ja. Und allemal relevanter als die Marken-Auf- und Pixelzählerei in dem Artikel. ;-) -- Smial 00:38, 29. Sep 2006 (CEST)
Die entewickelten Lösungen beruhen auf Ultraschall. Damit „schüttelt“ der Sensor den Staub ab. Wird u.a. von Sony & Olympus eingesetzt. --MB-one 16:02, 29. Sep 2006 (CEST)
Ultrawas? Is ja Bonzig! PS: Why not with a subwoofer? ;-) --Overclocker 16:18, 29. Sep 2006 (CEST)
Hä? Wird übrigens auch von Pentax bei den Modellen mit Antishake verwendet. Wobei die neue K10D zusätzlich noch eine spezielle Beschichtung auf dem Sensor hat (afaik gleiche Technik wie bei den neuen Pentax-Objektivvergütungen) der das Anhaften von Schmuddel vermindern hilft. -- Smial 20:13, 29. Sep 2006 (CEST)
Überarbeiten
Letzter Kommentar: vor 17 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
Der Artikel strotzt vor Redundanzen, Ungenauigkeiten und teilweise falschen Informationen. Außerdem voller POV - und „Textwüste“ wäre noch untertrieben. Wie konnte der je „lesenswert“ werden? -- Smial 00:27, 8. Okt 2006 (CEST)
Noch dazu ein ziemlich blödes Lemma. OK, es ist durch einen Redirect abgedeckt, aber Digitalkamera wäre doch eigentlich naheliegender. Hat wahrscheinlich historische Gründe. Da wäre eigentlich erst mal eine Festlegung nötig, was hier eigentlich drinstehen soll. Eine umfassende Abhandlung über alle Aspekte der Digitalfotografie kann das eh nicht sein, eigentlich müsste man sich dem Lemma entsprechend auf die Kamera beschränken und von da aus verlinken. Aber da in den fotografischen Artikeln der deutschen Wikipedia sowieso eine Grobstruktur fehlt und frischfröhlich redundante Artikel angelegt wurden, kann auch die Strukturlosigkeit dieses Artikels nicht ganz verwundern. Den "Lesenswert" hat der so nicht verdient. MBxd1 01:17, 8. Okt 2006 (CEST)
Frage ist auch, wo man eine Grundrenovierung und -Strukturierung der technischen Fotoartikel einstielt. Portal:Fotografie scheint mir reichlich tot zu sein. -- Smial 17:28, 8. Okt 2006 (CEST)
Eigentlich kümmert sich da niemand systematisch drum, es hat wohl auch niemand einen Überblick, was es an Artikeln überhaupt gibt. Zu einigen anderen fototechnischen Themen gibts gerade Redundanzdiskussionen, aber die interessieren auch niemanden so recht. Und hier könnte man eigentlich auch noch einen Redundanzbaustein zu Digitalfotografie reinklatschen. Da sind die selben Bilder drin (samt Kamera auf dem Küchentisch), großenteils die selben Inhalte und "lesenswert" ist er auch. Der Artikel macht aber noch einen etwas besseren Eindruck, da passen Lemma und Inhalt noch aufeinander. Die kleinen Artikel zu technischen Fachbegriffen sind großenteils gut gemacht, das ist eine gesunde Basis, so dass man auch immer bedenkenlos verlinken kann. Aber die übergreifenden Artikel sind zum Teil katastrophal. Es gibt noch schlimmeres als den hier, ich "empfehle" den Artikel Chronologie der Fotografie, der wurde (wie auch andere Fotoartikel) offensichtlich von einem Minolta-Freund zugespamt, grobe Fehler sind auch drin. Da kann man wirklich die Lust verlieren. Ich hab da leider auch kein Konzept und demnächst auch nur sehr bedingt Zeit. Obendrein hatte ich als nächstes eigentlich bestimmte kamera- bzw. firmenbezogenen Artikel im Auge (u. a. Kyocera/Contax, das muss unbedingt wieder aufgesplittet werden). Was diesen Artikel betrifft, bleibt wohl nix weiter übrig, als den Lesenswertstatus abzuerkennen und ihn dann von Grund auf neu zu fassen. Aber dazu müsste eine Einigung her, was da drinstehen soll. So redundant mit Digitalfotografie kanns jedenfalls nicht bleiben. MBxd1 18:05, 8. Okt 2006 (CEST)
Genau diese Fragen (Renovierung des Bereichs Fotografie) diskutieren wir schon seit einiger Zeit schon auf einigen Baustellenseiten, was bisher zum Portalneustart und zur Wiederbelebung des Wikipedia:WikiProjekt Fotografie geführt hat. Es wäre toll wenn wir dort in größerer Runde einen inhaltlichen Schlachtplan erarbeiten könnten. --NasenBV14:58, 11. Okt. 2006 (CEST)
Sicher sollte das alles in vernünftigem Kontext stehen, aber möglicherweise übernehmen wir uns damit. Man muss wohl doch häppchenweise anfangen, solange man nix wegschmeißt. Zu diesem Artikel: Den kann man wohl nur in einem Durchgang komplett neu fassen. Hinzu kommt, dass ich ganz gern das Lemma wechseln würde; im normalen Sprachgebrauch heißt es nun mal Digitalkamera. Ich weiß wohl, dass der Begriff unpräzise ist, weil damit theoretisch auch Überwachungskameras, Webcams und digitale Videokameras gemeint sein können, aber mit "Digitalkamera" meint man doch eigentlich wirklich nur digitale Stehbildkameras für fotografische Zwecke. Oder sieht das jemand anders?
Wie wäre dann wikipediatechnisch die Verfahrensweise zu sehen, den Artikel Digitalkamera (z. Z. Redirect hierhin) parallel komplett neu zu schreiben und das hier in einen Redirect umzuwandeln? Das erlaubt den direkten Vergleich beider Versionen und eine Nachbearbeitung des neuen Artikels, bevor man den alten wegschmeißt. Ich weiß wohl, dass man bei dieser Verfahrensweise keinen einzigen Satz rüberkopieren darf. Ich weiß auch, dass das ganze trotzdem einigermaßen zügig abgewickelt werden muss, weil massenweise Links auf die beiden Artikel zeigen. Die Geschichte der Digitalkamera ist zwar aufhebenswert, aber hier eigentlich falsch. Die im ersten Teil davon beschriebenen Digitalkameras sind ja genau keine digitalen Fotoapparate. Sollte man das u. U. auslagern (bzw. als Rest in der Ruine dieses Artikels belassen und dann auf ein passendes Lemma verschieben)?
Zum Inhalt: Hier sollten nach einer Definition die verschiedenen Bauformen von Digitalkameras und deren Komponenten genannt werden. Damit wird dann auch die bisherige Dominanz der Kompaktkameras gebrochen und man weiß wenigstens, um was es gerade geht. Aspekte der Kaufberatung haben weder hier noch sonst in der Wikipedia was zu suchen. Dieser Artikel ist nicht dazu da, dass man nach seiner Lektüre einkaufen gehen kann. Teilaspekte werden in verlinkten Artikeln erklärt. Wenn diese Verfahrensweise im Groben akzeptiert wird (einschließlich der beiden vorhergehenden Absätze), könnte ich mich vielleicht in ein paar Tagen (oder auch etwas mehr) daranmachen. Unschlüssig bin ich noch, was aus Digitalfotografie wird, ich hätte jedenfalls keine Skrupel, den zu plündern (z. B. Auflösungstabelle). MBxd120:42, 11. Okt. 2006 (CEST)
Lesenswert-Wiederwahl, 8. Oktober 2006 (gescheitert)
Letzter Kommentar: vor 17 Jahren4 Kommentare4 Personen sind an der Diskussion beteiligt
Der Artikel strotzt vor Redundanzen, Ungenauigkeiten und teilweise falschen und veralteten Informationen. Außerdem voller POV - und den als „Textwüste“ zu bezeichnen, wäre noch untertrieben. Wie konnte der je „lesenswert“ werden? Kontra -- Smial 00:39, 8. Okt 2006 (CEST)
...
ÜA und LW-Wdw??? Kontra --Overclocker 19:18, 8. Okt 2006 (CEST)
Kontra Keine klare Linie erkennbar. Das liest sich wie ein "zu Tode ausgebauter Stub". Dinge wie "Jeder Satz ein Absatz" ließen sich noch schnell korrigieren, aber in Gänze ist das über Strecken einfach nur liebloser Aufzählstil. --jha 21:20, 8. Okt 2006 (CEST)
kontra - wurde wohl von Leuten als lesenswert eingeschätzt, die nicht viel von der Materie verstehen. Spielzeug- oder Profiklasse einfach anhand der Megapixel festzumachen ist schonmal völlig falsch, der Stil zieht sich sinngemäß durch den ganzen Artikel. --Ralf 21:26, 8. Okt 2006 (CEST)
vllt. sollte wir den Artikel einmal durchs Review jagen, bevor wir dann und wieder mit der Neuwahl beschäftigen. mfg --- Maneckeоценка¿ | обсуждения¡ 23:45, 8. Okt 2006 (CEST)
Letzter Kommentar: vor 17 Jahren2 Kommentare1 Person ist an der Diskussion beteiligt
Ich bezweifele, dass es tatsächlich Digitalkameras mit CD-Laufwerk gibt, mir ist zwar bekannt, dass es Camcorder mit DVD-Laufwerk gibt, aber Kameras mit CD-Laufwerk sind mir absolut unbekannt. Runetyper (18:54, 29. Dez. 2006) (nachsigniert -- Smial19:37, 29. Dez. 2006 (CET))
Letzter Kommentar: vor 17 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
Die alten analogen Filme hatten eine Haltbarkeit von etwa 100 Jahren - ohne jedwede technische Hilfsmittel.
Wie können digitale Bilder über einen solchen Zeitraum sinnvoll gesichert werden ? In 100 Jahren gibt es sicherlich keine PC oder CD oder DVD mehr.... Technikus15:20, 12. Feb. 2007 (CET)
Letzter Kommentar: vor 16 Jahren5 Kommentare2 Personen sind an der Diskussion beteiligt
Gibt es einen Artikel darüber, wie mit Digitalkameras Dokumente fotografiert werden können / sollten? Auch wenn ich weiß, dass WP kein Ratgeber sein will, wird die Wissensseite doch, realistisch gesehen, oft genutzt, um Problemfragen klären. (Hier also: Wie und mit welcher Kamera kann ich meine Papierablage am besten digitalisieren? Ich habe mit einer Olympus FE-170, die einen eigenen Dokumentenmodus besitzt, schlechte Erfahrungen gemacht. Wenn z. B. eine Zeitungsseite als ganzes archiviert werden sollte. Nicht für OCR. Wenn die Qualität für OCR ausreichen würde, wäre das aber natürlich ideal.) Hier also die Frage: Gibt einen entsprechenden Artikel in WP, den ich trotz einigen Suchens nicht gefunden habe? Könnte er angelegt werden? Ich würde mitmachen.
Ich habe testweise mit einer 5 Mpixel-Kamera Seiten aus einem knapp A5-großen Buch abfotografiert, das ich wegen Bruchgefahr nicht aufgefaltet auf den Scanner legen kann. Der Dokumentenmodus (Schwarzweiß, TIFF) ist unbrauchbar, die vergilbten Seiten sind je nach Belichtungseinstellung entweder mit schwarzen Pünktchen und zerissenen Flächen übersät oder aber die Buchstaben werden zu dünn und fransen aus. Die JPGs habe ich in Graustufen umgewandelt und an den FineReader verfüttert, das funktionierte erstaunlich gut, sogar mit Layout-Erhaltung. Wichtig dabei ist: Zoomobjektive verzeichnen je nach Brennweiteneinstellung relativ stark, OCR hat mit gebogenen Textzeilen große Probleme, insbesondere wenn hoch- oder tiefgestellte Zeichen vorhanden sind. Aber es gibt eigentlich immer eine Einstellung, bei der die tonnen- oder kissenförmige Verzeichnung des Kameraobjektivs minimal ist, bei meiner kompakten Ricoh ist das zufällig bei längster Brennweite der Fall, bei anderen Kameras kann es irgendwo zwischen Weitwinkel- und Telestellung liegen. Bei größeren Vorlagen und kleinen Typen dürfte die Auflösung nicht reichen, Schreibmaschine auf A4 sollte aber noch gut gehen. -- Smial12:38, 19. Aug. 2007 (CEST)
hier ist ein RTF, in dem die OCR-Ergebnisse einer Buchseite zu sehen sind, unterschiedliche Belichtungen. Man berücksichtige bei der Beurteilung der Qualität, daß da kursive Schriften und allerlei Layout-Tücken drin sind. -- Smial14:40, 19. Aug. 2007 (CEST)
Ich habe mal die Struktur eines möglichen Artikels auf meiner Benutzerseite angelegt. Wer Zeit, Lust und Kenne hat, ist herzlich eingeladen, mitzuschreiben.
Letzter Kommentar: vor 16 Jahren5 Kommentare3 Personen sind an der Diskussion beteiligt
Laut dieser Quelle hier ist die Größe gewöhnlicher Kamera-Photosensoren so gering, dass jenseits von 6 MP zu wenig Licht auf den einzelnen Pixel-Sensor trifft und von der Elektronik als Rauschen erkannt und daher korregiert wird. Ist dies richtig? Wenn ja, kann man dann für die noch kleineren Sensoren in Handycams sagen, dass 3 MP schon grenzwertig sind? 84.173.192.6323:55, 23. Nov. 2007 (CET)
Mobiltelefonkameras kenne ich nicht, von der durchweg gruseligen Qualität mit so etwas erstellter und in die Wikipedia hochgeladener Bilder abgesehen. Richtig ist, daß der Megapixelwahn bei kleinen Sensoren in der Praxis zu zwei hauptsächlichen Problemen führt: Verringerter Kontrastumfang und erhöhtes Rauschen. Beides versuchen moderne Kameras mehr schlecht als recht durch aufwendige Berechnungen zu kaschieren. Die Ergebnisse sehen dann auch schon mal recht impressionistisch aus. Falsch ist, daß 6MPixel genug seien. Ist der Sensor groß genug, kann man ohne weiteres auch deutlich mehr Pixel unterbringen. Entscheidend ist die Größe der einzelnen Pixel, aber Zahlenwerte wie 1.8 µm oder 6 µm lassen sich wohl nicht so öffentlichkeitswirksam präsentieren. -- Smial12:22, 24. Nov. 2007 (CET)
D.h. Spiegelreflexkameras haben eher 6 µm (Länge, Breite oder quadratisch?) und der Rest 1,8 µm? Vermutlich sind dann die Pixel in Handycams noch kleiner. 84.173.227.3113:48, 24. Nov. 2007 (CET)
Irreführendes Foto
Letzter Kommentar: vor 15 Jahren10 Kommentare5 Personen sind an der Diskussion beteiligt
Digitale KompaktkameraFrontansicht der Canon PowerShot A720ISohne Blitzschuh, ohne Tiefenschärfe, genauso schlecht... ;)Ohne Sucher, ohne Blitzschuh. Typischer?
Das Foto der G3 würde ich gerne tauschen, da ein Blitzschuh eine absolute Ausnahme an einer Kompaktkamera darstellt und stattdessen das eines aktuellen Modells einstellen. Ausserdem ist das Foto mit dem selben Fotoapparat aufgenommen und somit auch hinsichtlich der Bildqualität aussagekräftiger als das der G3, die gar nicht mit der G3 aufgenommen wurde. --Schwarzschachtel11:52, 19. Mär. 2008 (CET)
Mach ein besseres Bild der Kamera, dann können wir über nen Austausch reden. Derartig miese Bildqualität hat im Artikel nix verloren. --Felixfragen!11:55, 19. Mär. 2008 (CET)
Aber die Bildstruktur ist eine Katastrophe. Auf dem Foto ist nichts zu erkennen, unscharf isses auch und die Fusseln hättest du ja wenigstens vorher mal abputzen können. --Felixfragen!11:59, 19. Mär. 2008 (CET)
Die Bedienungselemente der Kamera sind nicht sichbar. Die Kamera sollte von oben rechts aufgenommen werden (wie beim anderen Bild). Geht natürlich nur mit einer zweiten Kamera, nicht im Spiegel wie jetzt --Finte12:03, 19. Mär. 2008 (CET)
Es kann ja als Beispiel dienen, wie mit einer modernen Kamera auch ein Laie sich einfach vor einen Spiegel stellen kann und trotzdem ein brauchbares Bild entsteht. Klar habe ich keine Profiausrüstung, die Waschbeckenbeleuchtung ist aber immer noch häufiger in Privathaushalten vorzufinden als eine professionelle Fotowerkstatt mit einem Könner hinter dem Sucher. Es war ein Schuss "aus der Hüfte" und ich war baff darüber, wie gut gelungen schon der erste Schuss war. Das ist wesentlich aussagekräftiger als eine Hochglanzbroschüre über dieses Gerät. --Schwarzschachtel12:05, 19. Mär. 2008 (CET)
Ich hätte die Möglichkeit ein Übersichtsfoto zu machen (z.B. mit Canon IXUS 85 IS, PowerShot A710IS und einer EOS 450D drauf). Das würde für den Artikelanfang wesentlich besser passen, und die anderen Bilder könnte man dann zur Illustration der Kameraklassen verwenden. Meinungen dazu? -- Wookie14:12, 1. Jul. 2008 (CEST)
Prinzipiell wäre ein solches Foto mit drei Kameras aus den verschiedenen Klassen sinnvoll, also eine schicke Kompakte, eine nicht zu fette Bridge und eine DSLR. Aber bei drei Modellen von Canon hätte ich Bauchschmerzen, es sollten m.E. unbedingt unterschiedliche Hersteller sein und keinesfalls Exoten. Das hat nichts mit Qualität zu tun, aber es sähe einfach zu sehr nach Pushen einer Marke aus. -- Smial15:49, 1. Jul. 2008 (CEST)
Okay, das stimmt natürlich. Bei den Bridgecams und den DSLR hab ich nicht soviel Auswahl, da hier alle nur Canon haben ;-) Aber eine andere Kompaktkamera sollte sich auftreiben lassen. -- Wookie18:50, 1. Jul. 2008 (CEST)
digitalzoom ist natuerlich Muell...
Letzter Kommentar: vor 15 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
aber wird nicht vor der JPG-Wandlung gezoomt? Dadurch evtl. weniger Daten oder geringfügig mehr Details (weil der Speicherplatz nicht für das uninteressante Drumherum draufgeht)? --88.74.147.6021:07, 5. Jul. 2008 (CEST)
Das hört sich an, als ob der erste Satz auf eher billige Massenware gemünzt ist, der zweite auf hochwertigere Modelle. --PeterFrankfurt00:37, 21. Dez. 2009 (CET)
Frage
Letzter Kommentar: vor 14 Jahren3 Kommentare3 Personen sind an der Diskussion beteiligt
Kann mir jemand sagen wie der Effekt auf meinen Bildern heisst wo in der Sonne ein schwarzer Fleck ist der dann gespiegelt in den
Die dunklen Flecke sind sicherlich durch massive Überbelichtung bzw. Übersteuerung des Sensors und/oder der nachfolgenden Verstärkerelektronik entstanden. Ob das ein Sensoreffekt ist oder durch seltsame Weiterverarbeitung in der Kamera entstanden ist, kann ich nicht sagen. Da müßte mal ein Fachmann für CCDs her. Wäre das Bild auf herkömmlichem Filmmaterial entstanden, würden wir eine echte Solarisation sehen. Der helle Fleck dürfte durch interne Reflexionen oder eben Lens Flare entstanden sein. Btw.: Lang andauernde Belichtungen dieser Intensität können den Bildsensor schädigen. Da gab es irgendwo im Netz mal ein schönes Beispiel einer Reihenbelichtung, bei dem die wandernde Sonne einen bleibenden Streifen auf dem CCD hinterließ. -- smial03:03, 3. Mär. 2010 (CET)
Kleinbild-äquivalente Brennweite
Letzter Kommentar: vor 13 Jahren4 Kommentare3 Personen sind an der Diskussion beteiligt
Welche der beiden Möglichkeiten ist heutzutage normalerweise gemeint, wenn eine Brennweite angegeben ist, ohne dass dabei steht, ob die reale oder die KB-äquivalente Brennweite gemeint ist ? In der aktuellen Werbung habe ich z. B. 18-55 gesehen (Sony A290). -- Juergen 91.52.172.16109:45, 1. Nov. 2010 (CET)
Auf jedem einzelnen Objektiv und eigentlich auch auf jeder Kamera mit fest eingebautem Objektiv sollte die reale Brennweite verzeichnet sein. Bei manchen Kameras steht sowohl der reale Wert drauf als auch eine kleinbildäquivalente Umrechnung. In der Werbung wird bei Kompaktkameras sehr häufig nur der Äquivalentwert angegeben, da muß man entweder hoffen, daß auf dem Foto der reale Wert erkennbar ist oder aber man muß googeln. Bei Spiegelreflexkameras habe ich bisher auch in der Werbung immer nur die Realwerte gelesen, aber es mag natürlich sein, daß irgendein Prospektfuzzi das mal anders macht. Bei der Sony dürfte das üblicherweise im Kit mitgelieferte Standardzoomobjektiv gemeint sein, mithin mit "echter" Brennweitenangabe, also eins, das etwa den Bildwinkel eines 28-85mm an Kleinbildformat entspricht. -- smial11:09, 1. Nov. 2010 (CET)
Danke fuer die Auskunft. Kennst Du eine Digicam-Website, die die Verlaengerungsfaktoren bzw. die realen Sensorgroessen diverser DSLR-Modelle zusammen mit den Brennweiten der Kit-Objektive tabellarisch auflistet, so dass ich die fuer mich interessanten mit ausreichendem Bildwinkel leicht herausfinden kann ? Den fuer mich interessanten Bildwinkel selbst, entsprechend der kleinbild-äquivalenten Brennweite, habe ich noch nirgendwo gelistet gesehen, wahrscheinlich deshalb, weil er eben nur aus Angaben fuer Kamera und Objektiv zusammen berechnet werden kann. -- Juergen 91.52.154.1909:59, 2. Nov. 2010 (CET)
Ich vermute, daß es viele Seiten gibt, die sich mit dieser Angelegenheit befassen, eventuell hilft dir aber zunächst schon Formatfaktor weiter. -- smial17:35, 2. Nov. 2010 (CET)
Punkt "weitere Entwicklung"
Letzter Kommentar: vor 15 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
"Digitalkameras wurden ab Mitte der 1980er Jahre zunächst vorwiegend von professionellen Fotografen im Bereich der Studio-, Mode- und Werbefotografie sowie ab Mitte der 1990er Jahre auch in der Reportagefotografie eingesetzt. Frühe serienreife Modelle wurden von Apple (Apple QuickTake), Casio (QV-Series), Sony (Mavica) und Canon (Ion) angeboten; Konica Minolta (Dimage), Nikon (Coolpix) und Olympus (Camedia) u. a. folgten mit eigenen Modellreihen."
Die Fotografen, die in den 80ern bereits Digitalkameras nutzten, möchte ich gern einmal sehen! Bei den genannten Studio-, Mode- und Werbefotografen waren analoge Mittelformatkameras am verbreitetsten, weil sie die beste Qualität lieferten. Was sollten Fotografen damals mit unbezahlbaren 0,5-Megapixel-Modellen anstellen? Kann der Verfasser dieses Abschnitts einen Beleg dazu liefern?
Dann steht da noch, dass ab Mitte der 90er Jahre Digicams in der Reportagefotografie eingesetzt wurden und gleich darauf folgt eine Aufzählung von frühen Digicams. Mit einer Apple QuickTake dürfte aber kaum ein Berufsfotograf unterwegs gewesen sein, da die genannte Kamera lediglich VGA-Auflösung hatte... (nicht signierter Beitrag von78.53.196.8 (Diskussion) 21:51, 2. Feb. 2009 (CET))
Da gibts ein paar Missverständnisse. Sowohl bei Dir als auch im Artikel. Bei den Studiofotografen hatte die Digitalfotografie damals noch keine Chance. Der erste professionelle Einsatzzweck war die Pressefotografie. Da sind die Qualitätsanforderungen weitaus bescheidener. Der eigentliche Durchbruch in diesem Bereich kam aber auch erst ab 1999 mit der Nikon D1. Das Missverständnis im Artikel ist das Ineinanderschmeißen von Still-Video-Kameras mit Digitalkameras. Das zieht sich durch weite Teile der Wikipedia, deshalb ändere ich jetzt zunächst mal nichts am Artikel. MBxd122:44, 2. Feb. 2009 (CET)
Frage zur Belichtungszeit
Letzter Kommentar: vor 13 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
Vielleicht kann das jemand im Artikel erläutern:
Bei einer analogen Kamera treffen die Photonen während der gesamten Belichtungszeit nacheinander auf und beeinflussen das Bild gleichermaßen. Eine digitale Kamera macht ja tatsächlich eine ganze Reihe von Messungen über die Belichtungszeit, aus denen dann ein Mittelwert gebildet wird.
Dazu muss die Kamera aber:
sämtliche Messungen speichern (Problem: Speicherplatz) oder
die Messungen über eine Tiefpassfilterung (Sn=Sn-1*(1-f)+SMessung*f verknüpfen (Problem: die letzten Messungen werden stärker gewichtet als die ersten, aus einem "Verwackeln" wird ein "Nachleuchten") oder
mit variablen, sehr feinen Wichtungsfaktoren f arbeiten (Problem: Rechenleistung)
Das ist einfach: Digitalkameras arbeiten bei der Belichtung ganz genau so wie solche mit Film: Auch der Bildsensor sammelt während der Belichtungszeit nacheinander die Photonen ein. Ausgelesen und weiterverarbeitet wird dann pro Bild genau einmal. Schau Dir einmal die Artikel zu CCD- und CMOS-Sensoren an. -- smial21:26, 12. Nov. 2010 (CET)
Frage zur Belichtungszeit II
Letzter Kommentar: vor 13 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
Müsste im Abschnitt "Bildpunkte und Auflösung" nicht auch erwähnt werden, dass bei Kameras mit überhoher Pixelzahl, die Belichtungszeit (zumindest) theoretisch zunehmen sollte, da die einzelnen, kleineren Pixel dann weniger Licht abbekommen? -- 46.114.60.14200:37, 11. Jan. 2011 (CET)
So pauschal kann man das nicht sagen. 1. Spielt hier auch die Sensorgröße eine Rolle. 2. Entwickelt sich die Sensortechnik immer weiter und Sensoren mit einem besseren Signal-Rausch-Verhältnis können daher auch bei kleinerer Pixelfläche (insgesamt höhere Pixelzahl) gelich gute Ergebnisse abliefern. --Cepheiden13:05, 16. Feb. 2011 (CET) P.S. wie definierst du "überhoher Pixelzahl"?
"EVIL" ist eine "Auferstehung" von "Subclub", keine Neuerfindung
Letzter Kommentar: vor 13 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
"EVIL"-Kameras sind eine "Auferstehung" der "Subclub"-Kameras der 197x-er-Jahre. Wiederholte Male in der Geschichte nach dem Zweiten Weltkrieg gab es den Versuch, neben dem 135er-Filmformat kleinere Filmformate am Markt zu platzieren, - ein Interesse, das sich nach dem Obsoletwerden des chemischen Films heute bei den Fotosensoren fortsetzt. Im Zusammenhang mit der Platzierung des Filmformats der 110er Kodak-Kassette wurden Subclub-Kameras angeboten, so etwa die Minolta 110 (http://en.wikipedia.org/wiki/Minolta_110_Zoom_SLR) und die Pentax 110 (http://en.wikipedia.org/wiki/Pentax_110). Die Objektive der Pentax 110 können über Objektivadapter noch heute an Micro-Four-Third-Kameras von Pentax benutzt werden, (etwa: http://www.enjoyyourcamera.com/Objektivadapter/an-Micro-FourThirds/Pentax-110-Micro-FourThirds-Adapter::3186.html). Ob Vergleichbares für Minolta Objektive und Sony-Kameras gilt, müsste man bei Interesse ermitteln, - (gibt es überhaupt Micro Four Third Kameras von Sony?). --84.142.137.21713:18, 5. Feb. 2011 (CET)
Dieser Abschnitt kann archiviert werden. Cepheiden 13:01, 16. Feb. 2011 (CET)
EVIL != CSC
Letzter Kommentar: vor 13 Jahren2 Kommentare1 Person ist an der Diskussion beteiligt
Im Gegensatz zu EVIL scheint die Bedeutung des Begriffs CSC noch nicht wirklich etabliert zu sein,[1] aber als CSC werden wohl auch Systeme ohne Sucher (nur Monitor) bezeichnet.[2] Somit dürfen die beiden Begriffe aber nicht, wie gerade im Artikel zu lesen, gleichgesetzt werden, CSC wäre wohl eher die Obermenge.
Hab mal den Abschnitt zu EVIL/CSC und was sonst noch so an Begriffen rumfährt in Spiegellose Systemkameras umbenannt und die Gleichsetzung aufgehoben. --Burkhard04:35, 22. Apr. 2011 (CEST)
Letzter Kommentar: vor 12 Jahren5 Kommentare3 Personen sind an der Diskussion beteiligt
Hallo, gibt es einen speziellen Grund, warum bislang digitale Kamerarückwände im Artikel nicht erwähnt werden? --Cepheiden14:10, 1. Aug. 2011 (CEST)
Tja, das ist halt eine dieser Lücken, die auf ihre Füllung warten. Eine andere Lücke ist, dass Spiegelreflexkameras (mit Sucher und Spiegel) zwar dauernd nebenbei erwähnt werden, aber kein eigenes Unterkapitel für sie existiert. Das sollte man auch nachholen. --PeterFrankfurt00:54, 3. Aug. 2011 (CEST)
Vielleicht hängt das auch damit zusammen, dass nicht jede Digitalkamera eine "digitale Kamerarückwand" hat, dafür aber einen "Monitor"? Schwenkbare Monitore beispielsweise wären mit "Kamerarückwand" wohl unpassend bezeichnet. Monitore finde ich im Artikel ein paar mal - aber auch eher nur nebenbei - erwähnt. --Burkhard22:35, 4. Aug. 2011 (CEST)
Monitore? Was hat denn eine digitale Kamerarückwand mit einem Minitor zu tun? Bei digitalen Kamerarückwänden geht es um die Bildaufnahme (digitale Bildaufnahme für eigentlich filmbasierte Kamerasysteme) nicht die Wiedergabe. --Cepheiden10:07, 5. Aug. 2011 (CEST)
Nein. Er meinte meinem Eindruck nach lediglich, dass diese Monitore (statt optischen Suchern) ebenfalls (wie die Rückwand) noch nicht richtig erläutert würden. Dem habe ich ja gerade versucht abzuhelfen. --PeterFrankfurt03:13, 6. Aug. 2011 (CEST)
Patent worauf?
Letzter Kommentar: vor 12 Jahren8 Kommentare4 Personen sind an der Diskussion beteiligt
Der Satz ist unverständlich: "Das erste Patent auf alle flachen (Bild-)Schirme, die optische Bilder stabil (solid-state) aufnehmen und aufbewahren können, wird 1968 beantragt. U.S. patent # 3,540,011"
Auf was für eine Art "Schirm" wurde ein Patent erteilt? Doch wohl kein Display, oder? Ist da vielleicht der Bildwandler gemeint? Wieso auf "alle flachen Schirme" - alle denkbaren oder überhaupt möglichen, oder was? Wird nicht ein Patent auf ein bestimmtes technisches Verfahren, Gerät etc. erteilt? "solid-state" heißt doch wohl "Festkörper" im Sinne des festen Aggregatzustands wie z. B. in "solid state physics" = "Festkörperphysik", und es heißt nicht einfach nur "stabil". Und "optische Bilder aufbewahren" hört sich an wie eine schlechte Übersetzung aus dem Englischen. Und dann noch die Patentnummer hinten an den Satz drangeklatscht - kann das nicht in Klammern stehen? --Turdus16:26, 21. Nov. 2008 (CET)
Prinzipiell noch immer derselbe unverständliche Satz wie 2008: klingt wie aus Google Translate. Mit „stabil“ ist wohl nichtflüchtig gemeint (wie in Solid State Disk), aber was bitte soll ein „flacher Schirm“ sein?
Ja, ich habe mal wenigstens den einen Begriff ausgetauscht. Das mit dem Schirm ergibt sich dann auch noch aus dem englischen Artikel: Der Sensor ist nicht monolithisch, sondern besteht aus einer Matrix diskreter Photodioden, jeweils plus Speicherkondensator. --PeterFrankfurt02:23, 1. Feb. 2012 (CET)
Vielen Dank, so ist’s wesentlich besser.
(Auf die Idee, mir den englischen Artikel anzuschauen, hätte ich auch kommen können, sorry.) 09:28, 1. Feb. 2012 (CET)
Bitte nicht "solid state" mit Halbleitertechnik („semiconductor technology“) gleichsetzen. Festkörper ist nunmal die gängige Übersetzung von "solid state", auch wenn dieser deutsche Begriff vom Sinn her genauso unpassend ist wie im Englischen. --Cepheiden15:41, 1. Feb. 2012 (CET)
Ich möchte doch bloß wissen, was um Himmelswillen mir dieser Satz sagen will. Wenn das niemand herausfindet und entsprechend formuliert, bin ich dafür, den ganzen Satz zu löschen. 19:31, 1. Feb. 2012 (CET)
@Cepheiden: Doch, doch, doch, in solchen Bezeichnungen sind wir weit weg von der Physik, da meinen die die ANWENDUNG der Festkörpertechnik in Form von Halbleiterbauelementen, historisch im Gegensatz zur Röhrentechnologie. Und obwohl dieser Vergleichspartner kaum noch relevant ist, hat sich diese Sprechweise zumindest im angelsächsischen Bereich so erhalten. --PeterFrankfurt02:38, 2. Feb. 2012 (CET)
Letzter Kommentar: vor 12 Jahren11 Kommentare6 Personen sind an der Diskussion beteiligt
oder was ist das besondere an der kamera?
große sensoren in kompakten gibt es schon ewig. und die paar % kleineren MFT kameras und sony NEX (!) bieten auch große sensoren
-> es ist plumpe werbung, sonst nichts. (nicht signierter Beitrag von193.171.240.54 (Diskussion) 19:29, 18. Mär. 2012 (CET))
Du scheinst ja recht wenig Ahnung zu haben! Die Sony Nex ist eine Systemkamera mit Wechselobjektiven und keine Kompaktkamera. Nenne mir bitte Kompaktkameras, die mit einem ähnlich großen oder größeren Fotosensor arbeiten wie die G1X und die es angeblich schon "eine Ewigkeit" gibt. Es gibt keine. Richard Huber (Diskussion) 22:31, 18. Mär. 2012 (CET)
Die Sony R1 hatte das schon vor etlichen Jahren, die Sigma-Kompaktkameras auch allesamt. Im übrigen hat der Sensor der G1X nicht volle APS-C-Größe, und die Canon-APS-C-Sensoren sind eh schon kleiner als beim größten Teil der Konkurrenz.
Es spricht nichts dagegen, die abgebildeten Kameras auch mal gegen aktuelle auszutauschen (Konica gibts ja auch schon lange nicht mehr - das wirkt etwas verstaubt), aber die G1X ist keineswegs der Meilenstein, als der sie uns in der Bildunterschrift verkauft werden sollte. MBxd1 (Diskussion) 23:04, 18. Mär. 2012 (CET)
Nun denn. Die Sigma habe ich mir auch angesehen. Sie war für eine Kompakte unglaublich teuer. Außerdem hatte sie - soweit ich mich erinnere - eine feste Brennweite. Und typisch für alle Kompakte - die ich bisher hatte - war ein fest eingebautes Zoom-Objektiv mit - relativ - kleinem Fotosensor. In der Bildunterschrift stand je auch mit "annähernd APS-C-Sensor". Von "Meilenstein" war in der Bildunterschrift auch nicht die Rede. Woraus liest du das? Im übrigen denke ich, dass die G1X wohl ein Schritt in die "richtige Richtung" darstellt. Als Kompakte - gerade noch - handelbar, obwohl schon recht groß und auch relativ schwer. Andererseits nicht die Notwendigkeit mit Wechselobjektiven zu hantieren wie bei Systemkameras oder DSLR. Und wieso sollte ich für Canon Werbung treiben? Ich habe die Kamera gekauft und bin - im Vergleich zu den Vorgängern - recht begeistert. In diesem Sinne. Richard Huber (Diskussion) 09:48, 19. Mär. 2012 (CET)
Ich habe das "Opus delicti" nicht gesehen, aber eine Meinung zur G1X. Nämlich die, dass sie im Moment eigentlich keine Konkurrenz hat wegen einiger Alleinstellungsmerkmale. Die letzte Kamera mit ähnlichen Eigenschaften war die Sony R1, und die erreicht - einfach auf Grund ihres Alters - lange nicht die Leistungen der G1X. Oder gibt es noch eine Digitalkamera, mit der man lautlos ansehbare Bilder mit ISO 3200 machen kann? Insofern kann ich es nur begrüßen, wenn dieses Gerät hier wenigstens Erwähnung findet. Gruß, --Meyer-Konstanz (Diskussion) 12:31, 19. Mär. 2012 (CET)
Keine Ahnung wie die Leistung der SLT-Kameras (ohne klappenden Spiegel) von Sony bei ISO3200 sind, aber das Modell Alpha 77 hat auch einen APS-C-Sensor. Die Bilder sollten daher ähnliche Qualität haben und lautlos aufnehmbar sein. --Cepheiden (Diskussion) 12:46, 19. Mär. 2012 (CET)
SLT-Kameras haben - wie auch die spiegellosen Systemkameras - einen Schlitzverschluss. Und der ist nie auch nur annähernd lautlos. Eine NEX (ohne Spiegel) z.B. ist lauter als so manche DSLR. Kann zwar gut sein, dass eine SLT - schon wegen des massiveren Gehäuses - etwas leiser ist, aber lautlos ganz sicher nicht. So gut wie lautlos sind bislang nur Kameras, die einen Zentralverschluss im Objektiv - oder einen rein elektronischen Verschluss haben. Ersteres gibt es nur bei Kameras ohne Wechselobjektiv und Kamerasystemen größer als Kleinbild, letzteres soll beim Nikon-1-System möglich sein. Gruß--Meyer-Konstanz (Diskussion) 19:11, 19. Mär. 2012 (CET)
Das sind alles ziemlich am Rand liegende Aspekte. Die G1X ist nicht die einzige ihrer Art (neben den genannten Beispielen wäre noch die Fuji X100 zu erwähnen), und ich sehe auch keinen Anlass, die G1X im Artikel abzubilden. Den größeren Sensor sieht man ihr nicht an; und das Bild ist auch von der Qualität her keine Bereicherung.
Übrigens gibt es auch bei Systemkameras keinen Zwang, Objektive zu wechseln. Man kann auch einfach ein Objektiv immer dran lassen. MBxd1 (Diskussion) 20:28, 19. Mär. 2012 (CET)
Nun das entscheidende ist, dass es den Ojektivwechsel (z.B. NEX) ermöglicht! Die GX1 ist eine Kompakte mit fest verbautem Zoomobjektiv. Und die Fuji X100 hat ein Objektiv mit einem fest verbauten Objektiv, das weder wechselbar noch zoombar ist! Nochmal: Die G1X ist (noch) m.E. ziemlich einzigartig: gerade noch Kompaktformat, relativ großer Sensor, passables Zoom-Objektiv. Keine Wechselobjektive, keine laut auslösende Systemkamera, klapp- und drehbares Display und einigermaßen bezahlbar. Seit knapp 2 Jahren beobachte ich den Markt intensiv und fand bislang keine Digicam, die das kann. Richard Huber (Diskussion) 15:02, 20. Mär. 2012 (CET)
Obwohl etwas klobig und ziemlich häßlich kann man die G1X durchaus als ersten Vertreter einer Kompaktkamerageneration ansehen, die das Problem aller bisherigen Kompakten angeht, nämlich die berauschten Minisensoren abzulösen, dabei noch erträglich handlich ist und trotzdem einen für den Alltagsgebrauch gut nutzbaren Zoombereich bietet. Klar war die Sony R1 viel früher da, aber was war das für ein Trumm! Die spiegellosen Systemkameras sind mit entsprechendem Zoom allesamt erheblich größer als die Canon, die anderen Kameras mit fest eingebautem Objektiv haben keinen Zoom. Die NEX mit Pancake-Weitwinkel ist zwar deutlich kleiner, aber hat dann auch keinen Zoom, nimmt man die Kitlinse hinzu, ist sie wieder viel schlechter verstaubar. Und zumindest meine NEX-5 ist lauter als die Brenzlax K5, und die muß noch den Spiegel bewegen. (Außerdem von der Bedienung her eher ne Playstation als ne Kamera, aber das ist ein anderes Thema). Ich denke, daß bald einige weitere Anbieter auf den Zug aufspringen werden (Ricoh?) und es neben den Superkompakten, den Bridges (mit eingebautem Superzoom) und den Systemkameras eben eine weitere Klasse von Fotogeräten geben wird für den Anwender, der eine bezahlbare Alternative zu seiner DSLR sucht, wenn er das ganze Gerümpel mal nicht mitschleppen will, aber zumindest von der Sensorgröße her keine wesentlichen Einschränkungen gegenüber der "Großen" erleiden will. -- smial (Diskussion) 16:43, 20. Mär. 2012 (CET)
Die Fuji X100 war vorher da, und die ist auch nicht klobig. Die Sony R1 ist nicht wegen des großen Sensors so groß, sondern wegen des großen Brennweitenbereichs. Kameras mit kleinerem Sensor waren damals auch nicht kleiner. Der erste Vertreter einer neuen Generation ist die G1X daher ganz sicher nicht, selbst wenn man die Sigmas ignoriert. Wenn sich diese Kameraklasse dauerhaft etabliert, ist das auch eher was für den Artikeltext als für ein Werbefoto mäßiger Qualität. MBxd1 (Diskussion) 19:23, 20. Mär. 2012 (CET)
Schwieriger, Bild zu speichern als kurzen Film?
Letzter Kommentar: vor 11 Jahren9 Kommentare4 Personen sind an der Diskussion beteiligt
"...da es schwieriger war, ein einzelnes Bild zu speichern als einen kleinen Film."
Kann jemand erklären, warum das so ist? Bei einer Recherche im Internet finde ich mehrere Stellen, die den gleichen Wortlaut haben, aber eine Erklärung fehlt auch dort.
--Mistmano (Diskussion) 21:09, 7. Nov. 2012 (CET)
Hi. Also wirklich wissen tue ich es nicht, aber vor noch nicht all zu langer Zeit (~10 Jahre(?)) war es ja üblich, Filme noch auf Kassetten zu speichern. Und (so meine ich) war die Technik selber - nämlich sowohl die (Video)kamerainterne Verarbeitung, als auch das Speichern auf Kassette - analog, ähnlich dem analogen Fernsehen. Aber ein einzelnes Foto - also müsste quasi ein stehendes Signal sein - analog zu speichern, ist etwas anderes als einen laufenden Film (Signal). Und zudem gab es im Jahre 1970 auch nur vergleichsweise wenigen und sehr teuren Digitalspeicher (Festplatten, Flash, RAM). Soweit mein Wissen bzw. Vermutungen. Dazu bräuchten wir nun einen Experten, welcher sich mit dem Stand der Technik zu dieser Zeit gut auskennt. --#Reaper (Diskussion) 21:32, 7. Nov. 2012 (CET)
Danke für die Info. Aber: Bandlaufwerke (vor einigen Jahren zur Datensicherung verwendet) speichern doch auch in "Kassettenform" und dort kann ich doch auch "statische" Daten abspeichern, oder? Oder ist der Speicherprozess dort ein anderer? --Mistmano (Diskussion) 23:03, 13. Nov. 2012 (CET)
Öhm, an die Bandlaufwerke habe ich gar nicht gedacht gehabt. Und dass es die bereits schon 1970 gab, war mir auch eher nicht bekannt. Somit wäre dann meine Aussage, dass es 1970 "..wenigen und sehr teuren Digitalspeicher" gab wohl auch eher hinfällig, Bandlaufwerke sind ja (auch) digital. Hmm.. (Im übrigen werden die aber immer noch eingesetzt. ;) ) Mittlerweile hat Benutzer:Bautsch (diff) ja selbst etwas ergänzt, ich würde aber gerne wissen, ob das nun eher auch eher nur Vermutung von ihm ist, oder ob es dafür auch Quellen/Beweise gibt? Grüße, --#Reaper (Diskussion) 18:05, 15. Nov. 2012 (CET)
Anfangs wurde ja gar nichts gespeichert, weder Stehbiler noch Bewegtbilder. Die Bezeichnung "Bildaufzeichnungssensor" war verwirrend, daher hab ich "aufzeichnungs" entfernt. --Bautsch (Diskussion) 11:28, 16. Nov. 2012 (CET)
"...da es mit analoger Technik mangels Pufferspeicher einfacher ist, eine kontinuierliche unsynchronisierte Filmsequenz aufzuzeichnen, als nur ein einziges, zeitlich exakt definiertes Bild..." - Das wäre dann ja die Erklärung, warum es schwieriger ist, ein Bild zu speichern als einen Film. Aber ehrlich gesagt habe ich das noch nicht richtig verstanden: Was hat der (fehlende) Puffer bei analoger Technik mit der Aufzeichnung eines Bildes zu tun? Warum genau ist dann die Aufzeichnung einer Filmsequenz einfacher? --Mistmano (Diskussion) 22:19, 20. Nov. 2012 (CET)
Das Videoband stellt genau einen solchen (analogen) Pufferspeicher dar, der ein paar Jahre zuvor noch nicht zur Verfügung stand. Die Bilder werden magnetisch aufgezeichnet (respektive gespeichert) und können dann wieder gelesen werden. Die Erfinder konnten nur ein Live-Bild zeigen - direkt von der Kamera auf den Bildschirm, und das hat nun einmal Filmcharakter und nicht Stehbildcharakter. --Bautsch (Diskussion) 12:17, 21. Nov. 2012 (CET)
Mistmano hat nach dem Unterschied zwischen einer analogen Aufzeichnung eines Standbilds und der analogen Aufzeichnung eines Films gefragt. -- Smial (Diskussion) 12:22, 21. Nov. 2012 (CET)
Neue Schemazeichnung
Letzter Kommentar: vor 11 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
Hauptbestandteile einer Digitalkamera
Sorry, aber ich finde das neue Bild nicht wirklich gelungen. Was ist z.B. mit Verschluss, Rechnereinheit (Grafikprozessor), Autofocus-Sensoren (bei DSLR), optische Sucher. Der Blitz ist nicht zwingend Bestandteil und der Auslöser ist irgend wie überbetont gegenüber den anderen Bedienelementen. -- Koppi221:41, 20. Jan. 2010 (CET)
Ich gebe dir prinzipiell Recht. Den Auslöser würde ich durch "Bedienelemente" ersetzen. Eventuell sollte man die Grafik aber eher durch ein Blockdiagramm ersetzen, weil z.B. die Positionierung der Bedienelemente und einiger interner Elemente wie z.B. die CPU unterschiedlich ist. Übrigens fehlt auch noch der interne Flash-EEPROM-Speicher (ist bei jeder Kamera vorhanden, bei manchen Modellen wird da nur die Firmware gespeichert, bei anderen sind auch einige MB bis einige GB für die Bilder dabei) Ich würde übrigens eher "Rechnereinheit" schrieben als "Grafikprozessor", weil bei ersterem Ausdruck sind auch weitere Subsysteme wie der Arbeitsspeicher und der Bus enthalten, nicht nur der Prozessor. --MrBurns (Diskussion) 11:06, 21. Jan. 2013 (CET)
Überabtastung
Letzter Kommentar: vor 10 Jahren10 Kommentare3 Personen sind an der Diskussion beteiligt
Zitat: "neuer Trend zur Überabtastung ab (englisch: oversampling), bei der nicht mehr jede Pixelinformation in einem eigenen Bildpunkt gespeichert wird, sondern mehrere einfarbige Pixel zu einem mehrfarbigen Bildpunkt zusammengefasst werden"
Klingt nicht neu, sondern nach einer Beschreibung des üblichen Grundprinzips so ziemlich aller Digitalkameras - siehe Bayer-Sensor. - Was soll mir dieser Abschnitt also eigentlich sagen?--92.201.56.6913:09, 24. Sep. 2013 (CEST)
Der Unterschied besteht darin:
Bei Farbfilter-Arrays wird pro gespeichertem farbigen Bildpunkt (in der JPEG-Datei) nur ein Farbwert gemessen, und die fehlenden Farben werden aus den Nachbarpunkten interpoliert - die Anzahl der gemessenen einfarbigen Bildpunkte ist gleich der Anzahl der gespeicherten farbigen Bildpunkte (das ist also eine Unterabtastung = weniger gemessen als gespeichert).
Wenn mehrere ein- oder mehrfarbige gemessene Bildpunkte zu einem einizigen gespeicherten Bildpunkt zusammengefasst werden spricht man von einer Überabtastung - die Anzahl der gemessenen einfarbigen Bildpunkte ist deutlich größer als die Anzahl der gespeicherten farbigen Bildpunkte.
Ein guter Kompromiss ist ungefähr so viele Bildpunkte zu speichern, wie komplette Farbpunkte gemessen werden - Faustformel bei Bayer-Sensoren: Anzahl der Sensor-Pixel geteilt durch drei. Es ist also wegen der Unterabtastung und der eingebauten optischen Tiefpässe problemlos, die Bilder von einem 18-Megapixel-Sensor als 6-Megapixel-JPEG-Dateien zu speichern; es geht praktisch keine Information verloren, und die Bilder sind kleiner und können schneller weiterverarbeitet werden.
Diese Bayer-Faustformel ist in dieser Pauschalität Unfug. Mag sein, daß vor 10 Jahren "praktisch" keine Information verloren ging bei einer Drittelung der Pixelzahl, zumindest bei halbwegs modernen Kameras funktioniert die Interpolation jedoch heute so prächtig, daß bei Anwendung dieser "Formel" tatsächlich eine erhebliche Informationseinbuße gegenüber der vollen Auflösung eintritt. Siehe Beispielbilder. -- Smial (Diskussion) 15:45, 25. Sep. 2013 (CEST)
Vielen Dank für den anregenden Diskussionsbeitrag ! Meine Aussage mit dem guten Kompromiss betraf das Betrachten eines gesamten Bildes in normalem Betrachtungsabstand (Bildwinkel rund 45°) und nicht bei einem Betrachtungsabstand, wo das gesamte Bild nicht annähernd vollständig betrachtet werden kann, sondern nur ein relativ kleiner Bildausschnitt, den man dann viel besser gleich mit einer längeren Brennweiste aufgenommen hätte - das hätte ich wohl noch dazu sagen sollen. In der Miniaturdarstellung rechts, die auf meinem Monitor etwa der normalen Bildhöhe des gesamten Bildes entspricht, sehe ich keinen Unterschied zwischen den beiden Bildern. Das Bild in voller Bildauflösung hat noch nicht einmal ein Zehntel der aufgenommenen Bildzeilen und nur 1/72 der Bildpunkte des gesamten mit der Festbrennweite aufgenommnen Bildes - wofür sollte ein solch kleiner Bildausschnitt in der Praxis nützlich sein ?
Wie auch immer, auch die Beispielaufnahme in voller Auflösung ist weit davon entfernt, eine ebenmäßige Kontrastübertragungsfunktion zu haben. Bei der Nyquist-Frequenz ist nicht mehr besonders viel Modulation vorhanden: Wenn ich die Anzahl der Bildpunkte halbiere (Skalierungsfaktor 71% in x- und y-Richtung), dann kann ich im reduzierten Bild genausoviele Details erkennen, wie im Bild mit der vollen Auflösung, natürlich nur bei Anzeige mit gleicher Bildgröße (habe es gerade ausprobiert). Also kann die Anzahl der Bildpunkte wohl auch ohne weiteres wenigstens halbiert werden.
Zugegebenermaßen sind bei einem Drittel der Bildpunkte (Skalierungsfaktor 58% in x- und y-Richtung) im Beispielbild tatsächlich leichte Modulationsverluste bei sehr hohen Ortsfrequenzen sichtbar, wenn man die Anzeige stark genug vergößert. Bei der Pentax K-5 IIs wäre dieser Unterschied übrigens noch ein wenig deutlicher, weil die im Gegensatz zur K-5 II keinen optischen Tiefpassfilter verwendet. Auf der anderen Seite kommt in der Praxis aber hinzu, dass die meisten Zoomobjektive sowieso nicht in der Lage sind, bei Offenblende die für den Bildwandler theoretisch erforderliche optische Auflösung zu liefern. Von höheren eingestellten Lichtempfindlichkeiten als ISO 200, wie im Beispielbild, wollen wir in diesem Zusammenhang lieber gar nicht erst anfangen zu diskutieren, da wird es nämlich zunehmend unsinniger, in voller Bildauflösung zu speichern. --Bautsch (Diskussion) 19:59, 25. Sep. 2013 (CEST)
Es gibt heute Zoomobjektive, die eine bessere Auflösung bieten als meine Festbrennweite, die afaik eine rund 30 Jahre alte oder gar noch ältere Rechnung hat. Wobei die abgeblendet wirklich nicht ganz schlecht ist. Natürlich macht niemand solche vergrößerten Ausschnitte, um Nummernschilder abzubilden. Freilich kann man das Bild, aus dem die Ausschnitte stammen, bei gemäßigten 150dpi auf rund 50*80cm vergrößern, auf 1/3 der Pixelmenge verkleinert (das war diese "Faustregel") aber nur auf etwa 30*50cm. Bei 50*80 bleiben dann nur noch 90dpi übrig. Alles gerundet, es geht ja nur um Größenordnungen. Der Betrachtungsabstand ist dabei völlig unerheblich, denn die gute alte "6 Mpixel sind genug"-Regel gilt natürlich nur für "übliche" Betrachtungsabstände, ebenso verhält es sich mit den Zerstreuungskreisen. Das sind alles Konventionen, die teils heute nicht mehr gelten (0.3mm Zerstreuungskreis für Kleinbild - grotesk angesichts Megapixelmonstern wie die Nikon D800), teils nie gegolten haben, wenn es um Nutzungen wie z.B. in der Architektur- oder Werbefotografie geht. Nicht umsonst gab es immer schon Großformatkameras, um höhere Ansprüche zu befriedigen, die Pixelmenge eines 8x10"-Scans will man gar nicht wissen. Aber diese Konventionen und Nyquest und alles andere machen diese komische 1/3 Faustformel nicht gültig. Für die meisten Anwendungen sind 6 MPixel natürlich immer noch "genug", ich selbst lade meine Bilder meist in dieser Auflösung hoch, einfach, weil das für übliche Nachnutzung reicht und die Dateien nicht stundenlang mein DSL blockieren. Allerdings ist das Runterskalieren stets der letzte Schritt in der Bildbearbeitung, wie von dir oben angegeben zunächst herunterzuskalieren, um danach schneller bearbeiten zu können, geht in der Praxis schief. Nicht umsonst arbeiten viele zunächst mit 16-Bit-Tiffs, selbstverständlich in generischer Auflösung, wenn sie umfangreiche Manipulationen durchführen, um eben auf dem Weg zum fertigen Bild nicht bei irgendwelchen Zwischenschritten Verluste zu erleiden. -- Smial (Diskussion) 20:41, 25. Sep. 2013 (CEST)
Wir sind uns fast völlig einig, nur die Geschichte mit dem Betrachtungsabstand möchte ich gerne noch ein wenig vertiefen: Ein Werbeplakat schaut man sich selbstverständlich aus einem größeren Abstand an als einen 9 cm x 13 cm-Abzug. Die Punktdichte wird dann natürlich dem Format angepasst und nicht der Zahl der Bildpunkte - siehe auch Betrachtungsabstand. Die Gründe sind letztlich die Verteilung der Stäbchen auf der Netzhaut und die Kontrastempfindlichkeitsfunktion (CSF) des menschlichen Auges. Ansonsten sei noch mitgeteilt, dass die Farbstrukturtreuefunktion über der Ortsfrequenz (also der Bezug zu den Farbzäpfchen auf der Netzhaut) nur zu einem Bedarf von ungefähr zwei Millionen Farbpunkten führt (deswegen, kann man übrigens JPEGs auch so gut komprimieren, ohne dass dies zu nennenswerten Informationsverlusten führt). Merkwürdigerweise beschwert sich kaum ein Photograph darüber, dass seine digitale Systemkamera keine Farbstrukturen mit 500 Linienpaaren pro Bildhöhe abbilden kann, aber bei den Helligkeitsmodulationen ist es scheinbar äußerst wichtig, dass bei 2000 Linienpaaren pro Bildhöhe noch zehn Prozent Modulation vorhanden sind, die man im Gesamtbild sowieso nicht erkennen kann. Wenn die Modulation bei der Nyquist-Frequenz hoch ist, dann kann auch ein Full-HD-Bild mit "nur" zwei Megapixeln hervorragend aussehen, allerdings braucht man dann auch Kameras und Objektive, die bei 500 Linienpaaren pro Bildhöhe vollen Farbkontrast liefern und da wird es selbst im gehobenen Amateurbereich sehr eng...
Und wie gesagt, die komische Faustformel, war ein Vorschlag für einen Kompromiss (ich selber neige nach der Bearbeitung meiner Rohdaten inzwischen sogar eher zum Faktor vier bei der Reduktion der Bildpunkte). --Bautsch (Diskussion) 09:43, 26. Sep. 2013 (CEST)
Und übrigens: Bei 50 Millimeter Brennweite und Blendenzahl 8 hat das Airy-Scheibchen schon einen Durchmesser von rund 10 Mikrometern, so dass es viel größer ist, als der Pixelpitch der Pentax K5 II, der bei knapp 5 Mikrometern liegt. Also ist eine solche optische Abbildung völlig unabhängig von der optischen Qualität des (Zoom-)Objektivs schon allein deswegen beugungsbegrenzt. --Bautsch (Diskussion) 10:09, 27. Sep. 2013 (CEST)
Jetzt haben wir den Salat: Die Optik sagt: "Geht gar nicht", die Bilder, die aus der Kamera kommen, zeigen in voller Auflösung trotzdem mehr Informationen als runterskaliert. Man muß nur genau hinguggen. Und nu? Digitale Optimierungen verbieten, damit die Rechnungen Faustregeln wieder stimmen? -- Smial (Diskussion) 17:57, 4. Okt. 2013 (CEST)
Die Forscher beschäftigen sich mit der Eliminierung von geometrischen Abbildungsfehlern, was besonders gut bei der Verzeichnung, dem Randlichtabfall, beim Farbquer- und -längsfehler und eingeschränkt auch bei der sphärischen Aberration und bei der Bildfeldwölbung möglich ist. Wie beeindruckend gut das heute schon funktioniert, sieht man zum Beispiel beim Micro-Four-Thirds-System aber auch, wenn man die unkorrigierte tonnenförmige Verzeichnung von über zehn Prozent in den Rohdaten der Sony RX100 in Weitwinkelstellung mit den JPEGs vergleicht. Asphärische und apochromatische Objektive sind aufwendig und somit teuer und schwer. Was bei einfachen und leichten Feldlinsen auch nach der erwähnten Veröffentlichung nicht korrigiert werden kann, ist die quantenmechanische Beugung, und somit kann und wird keine optische Abbildung in der Größenordnung des jeweiligen Beugungsscheibchens eine einhundertprozentige Modulation haben. Bei halbem Durchmesser des Beugungsscheibchens geht man im Allgemeinen von einer in der Praxis vernachlässigbaren Modulation aus, nicht die Rede von noch kleineren Abmessungen.
Trotzdem ist es natürlich sehr beeindruckend, wenn man durch rechnerische Korrektur selbst mit einem "Flaschenboden" in diese Dimensionen vorstoßen kann. --Bautsch (Diskussion) 22:20, 4. Okt. 2013 (CEST)
Gerade für diese Umrechnerei deftiger Verzeichnungen benötigt man viele Pixel, um nicht zuviel hinzuerfinden zu müssen. Das Problem sieht man ja deutlich bei vielen Versuchen, stürzende Linien gewaltsam geradezuziehen, man kommt dann schnell in einen Bereich, bei dem man die Ausgabebildgröße drastisch verkleinern muß, um in den "gespreizten" Bildbereichen noch eine halbwegs taugliche Schärfe zu haben. Wenn ich aber vorher schon stark herunterskaliert gespeichert und archiviert habe, kann man typische nachträgliche Bearbeitungen, wie eben Drehen, Entzerren, Nachschärfen, Entrauschen so ziemlich vergessen. -- Smial (Diskussion) 10:01, 5. Okt. 2013 (CEST)
Und was ist ein "digital" aufgenommener Film ?
Letzter Kommentar: vor 10 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
In der Artikelgruppe um den Schriftsteller Yann Martel wird unter anderem erwähnt, dass einer seiner Romane verfilmt, aber "nicht" digital aufgenommen worden sei. Was also ist ein "digital aufgenomnmener" Film ? <kreuz des südens. 140214.> (nicht signierter Beitrag von84.163.94.212 (Diskussion) 17:54, 14. Feb. 2014 (CET))
Hmm, meinst Du Life of Pi: Schiffbruch mit Tiger? Der wurde allerdings (zumindest lt. Artikel) "digital gedreht". Zur eigentlichen Frage: Es gibt eigentlich 3 Möglichkeiten:
Aufnahme auf analogem Filmmaterial. Betrachtung mit analogem Filmprojektor
Aufnahme auf analogem Filmmaterial. Anschliessend Einscannen (Digitalisieren) des Materials. Betrachtung mit digitalem Equipment
Aufnahme mit Digitalkamera. Betrachtung mit digitalem Equipment.
"Digital gedreht" ist Variante 3. Dann existiert kein "anfassbares" Filmaterial. Wenn man also Sammler-DVD-Boxen mit "Original-Filmschnipseln" bekommt, dann wurde das ausbelichtet, also die Bits & Bytes in einem Ausbelichter auf analoges Filmmaterial kopiert.
Letzter Kommentar: vor 9 Jahren4 Kommentare3 Personen sind an der Diskussion beteiligt
Teile der Abschnitts Digitalkamera#Optisches System fallen hinsichtlich des Rests des Artikels aus dem Rahmen: Die technischen Formeln sind nur Physikern und Ingenieuren verständlich. Auf Laien wirkt das abschreckend. Gibt es vielleicht Ideen, wie man diese Informationen besser an anderer Stelle der Wikipedia unterbringt? --Hasenläufer (Diskussion) 21:25, 17. Nov. 2014 (CET)
Eventuell kann man auch einige Sachverhalte allgemeinverständlicher machen, indem man sie zusätzlich mit Hilfe der geometrischen Optik visualisiert. Die Formeln sind zwar auch geometrische Optik, aber für Laien nicht so leicht verständlich wie eine "Zeichnung". --MrBurns (Diskussion) 02:30, 20. Nov. 2014 (CET)
Ich halte den Verweis auf den Formatfaktor für korrekt und notwendig. Die Beispielrechnung kann aber ersatzlos raus. Schon die Annahme, 50mm sei die einzig wahre "Normalbrennweite" ist falsch, die Folgerung mit den zementierten 15.6% ist mithin mindestens irreführend. "Normalbrennweite" kann bei Kleinbild alles mögliche irgendwo zwischen 40 und 60mm sein. Der Absatz über den Digitalzoom sollte eine eigene Überschrift bekommen. -- Smial (Diskussion) 11:34, 20. Nov. 2014 (CET)
Ja klar, der Verweis auf den Formatfaktor ist korrekt und notwendig. Die Frage ist m. E., ob Inhalte aus dem Abschnitt „Optisches System“ dieses Artikels nicht besser im Lemma Formatfaktor aufgehoben wären, da sie technisch in die Tiefe gehen und in einem zutreffenden speziellen Artikel passender sind als in einem eher übergreifenderem und allgemeinerem Artikel „Digitalkamera“. --Hasenläufer (Diskussion) 03:14, 12. Dez. 2014 (CET)
Geschichte der Digitalkamera
Ich habe jetzt einmal im Rahmen meines Studiums die Anfänge der Digitalkamera nach www.digicamhistory.com hinzugefügt, allerdings reichen die Anfänge natürlich nicht aus und ich hoffe, dass sich noch jemand findet, der diese Geschichte ein Wenig erweitern kann.
Für alle diejenigen, die sagen die Geschichte der Digitalkamera fängt später oder früher an möchte ich empfehlen sich nocheinmal genau zu erkundigen um festzustellen ob es nicht ausufern oder zu sehr einschränken würde einen anderen Anfangszeiutpunkt zu wählen. (wir können ja nicht bei Adam und Eva anfangen) Gruß --Benedikt Jockenhöfer 01:02, 18. Jan 2006 (CET)
nur ein paar minuten?
Letzter Kommentar: vor 16 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
eine frage zum kapitel "Erfindungsphase". warum konnten die bilder auf der videodisk nur ein paar minuten gespeichert werden? gab es probleme mit dem medium? Elvis untot11:45, 8. Nov. 2007 (CET)
Chronologie der Fotografie - Entwicklung der Digitalfotografie
Letzter Kommentar: vor 15 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
Wer kennt sich aus und mag in Chronologie der Fotografie den Bereich der Entwicklung der Digitalfotografie auf das wesentliche kürzen? Die Chronologie ersäuft, besonders zum Ende hin, an endlosen Nennungen von Kameraneuerscheinungen, sodass man die wesentlichsten Entwicklungen nicht mehr nachvollziehen kann.-- Kunani18:39, 11. Feb. 2009 (CET)
Bildauswahl
Letzter Kommentar: vor 12 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
Bei den aktuellen drei Einleitungsbildern ist nicht ersichtlich nach welchem Kriterium sie ausgewählt wurden, außerdem sehen sie von vorn aus wie normale Rollfilmkameras. Ich möchte anregen, nur ein Bild zu verwenden, dafür eines, das ein Charakteristikum zeigt, beispielsweise das Display oder die Entnahme des Speicherchips. Das obere Bild habe ich bei Digitalfotografie eingesetzt, daher will ich es hier nicht nochmal einbauen. Hat jemand eine Idee für ein Bild? --Siehe-auch-Löscher19:09, 30. Jul. 2011 (CEST)
Zum Abschnitt "Funktionsweise"
Letzter Kommentar: vor 12 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
Dort lese ich:
Scharfstellung des Bildes
Abschätzen einer sinnvollen Belichtungszeit und Blende
Optische Projektion durch das Objektiv auf den Bildsensor
Die Darstellung scheint mir sehr auf eine digitale Spiegelreflexkamera bezogen zu sein. Bei (vermutlich) allen anderen Digitalkameras käme der letzte Punkt zuerst, denn zum Scharfstellen muss schon der Bildsensor ausgelesen werden.
Da könnte man doch glatt auf die Idee kommen, den Abschnitt "Bauformen einer Digitalkamera" vollkommen über den Haufen zu schmeißen und die Spiegelreflexkamera den anderen gegenüberzustellen.--Meyer-Konstanz (Diskussion) 14:31, 17. Mär. 2012 (CET)
Grenzen der visuellen Wahrnehmung
Letzter Kommentar: vor 11 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
"Das gesunde menschliche Auge....Bei einem normalen Sehwinkel von zirka 50° für die Bilddiagonale ergibt sich eine Anzahl von etwa vier Millionen Bildpunkten, die ohne Farbinformation unterschieden werden können."
Danke, dass ich und alle meine Mitmenschen mehr Bildpunkte in Vollfarbe sehen können. Bitte diesen Unsinn löschen. Empierisch geschätzt (vergleich DigiCam vs Auge auf 300m Entfernung) komm ich auf über 100MP pro Auge.
Mit dieser geringen Auflösung würde niemand mehr ein Haar in der Suppe erkennen, geschweige denn Menschen auf 300m eindeutig identifizieren (und dass auch noch ohne Zoom). (nicht signierter Beitrag von80.123.4.180 (Diskussion) 23:09, 5. Dez. 2012 (CET))
Nyquist-Frequenz
Letzter Kommentar: vor 8 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
Ich versuche diese Artikel Stückchenweise zu überarbeiten und zu aktualisieren. Bei der "Nyquist-Frequenz" bin ich aber etwas verwirrt:
Ich sehe 3 Fotos mit offensichtlich verschiedenen Kontrasten (egal wie auch immer man Kontrast definieren mag). Darüber steht: "In den folgenden identischen Ausschnitten einer digitalen Fotografie mit identischer Bildauflösung und mit demselben Kontrast bei der Grenzauflösung wird verdeutlicht, dass der Kontrast bei der Grenzauflösung beim Empfinden der Bildqualität eine eher untergeordnete Rolle spielt."
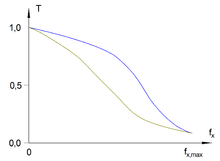
Hat das einer verstanden?--Friedrich Graf 18:10, 28. Jun. 2008 (CEST)
So wie es dort steht, NEIN. Aber die Nyquist-Frequenz ist maßgeblich für die tatsächlich darstellbare Steigung im Bild. 80.146.181.12315:58, 10. Dez. 2015 (CET)
(Belege:) CCD-Fehler
Letzter Kommentar: vor 8 Jahren6 Kommentare3 Personen sind an der Diskussion beteiligt
"Bei Kameras mit einer Auflösung von drei Megapixeln und mehr lassen sich CCD-Fehler kaum vermeiden" (sowie nachfolgende Ausführung).
Dazu fordere ich einen Beleg, insbesondere dafür, dass das heute (2015) noch immer gilt.
Intel kann CPUs fertigen, die aus 3 Milliarden Transistoren bestehen, und bei nur 1 Fehler wird das Teil zu Ausschuss. Dann werden sich doch fehlerfreie Sensor-Chips fertigen lassen mit 3..30 Millionen Fotodioden, und das bei annähernd NULL Ausschuss.
Es wäre vorher unbedingt zu definieren, was ein Fehler ist. Photodioden und -transistoren arbeiten nicht digital mit Nullen und Einsen, sondern mit quasikontinuierlichen Lichtmengen und analogen Strom- oder Spannungspegeln. Auch ein Bildpunkt, der nicht einen Totalausfall hat, kann fehlerhaft sein, wenn das Signalrauschen erhöht oder die Lichtempfindlichkeit reduziert ist und die Signaldynamik somit kleiner wird. Bei welcher Schwelle dieser Fehler nicht mehr toleriert wird, kann auf vielfältige Weise definiert werden, meines Wissen gibt es dafür (noch) keine Norm. Bei einem CCD-Sensor ist der Totalausfall eines Bildpunkts problematischer als bei CMOS-Sensoren, weil alle vorfolgenden Bildpunkte beim Auslesen dadurch beeinflusst beziehungsweise sogar blockiert werden. Ich halte es heute (2015) für praktisch ausgeschlossen, dass ein 16-Megapixel-Bildsensor (CMOS) in Kameras für Privatanwender weniger als ein Promille fehlerbehaftete Bildpunkte hat, in der Regel dürften es deutlich mehr sein. Das Belegen wird aber sicherlich schwierig, weil nicht gerne öffentlich darüber geschrieben wird. Ich sehe in dieser Thematik aber gar kein Problem, da die fehlerhaften Bildpunkte in der Regel durch die Signale der Nachbarbildpunkte ausgeglichen werden, bevor die sogenannten Rohdaten erzeugt werden. Das passiert heutzutage häufig sogar schon integriert auf dem Bildsensorchip.
Viele Kameras haben für die Ermittlung und Registrierung von solchen Pixelfehlern sogar eine Menüfunktion, die vom Anwender jeder Zeit aufgerufen werden kann, falls sich an der Situation mit den fehlerhaften Bildpunkten im Laufe der Zeit (zum Beispiel durch Einwirkung von Höhenstrahlung) etwas ändert. --Bautsch (Diskussion) 12:46, 22. Okt. 2015 (CEST)
Theoretisch könnten Fotozellen mit "reduziertem Spannungs-/Strompegel" noch im Werk vermessen werden, und der Prozessorchip muss entsprechend "Korrektur-rechnen". Wenn z.B. eine Fotozelle statt 0..1 V es nur noch auf 0 .. 0,5V bringt, wird sie nicht mehr auf 0..255, sondern auf 0..127 digitalisiert. *2 und es ist gerade mal ein Verlust des niederwerigsten Bits. Bei den 'Raw-Formaten' wird ausgesagt, dass die Fotozellen mitunter 10, 12 oder 14 Bit Genauigkeit liefern. Das bietet erhebliche Spielräume, dass Fertigungsungenauigkeiten dennoch "im erlaubten Rahmen" bleiben.
Der Artikel stellt darauf ab, dass solche Fehler sich auf das Endbild "durchschlagen" würden. Daher würde ich einen Pixel als 'fehlerhaft' bezeichnen, wenn die Foto-Elektronik es nicht mehr kompensieren kann.
Im Prinzip ist das auch so, nur dass eine Fotozelle etwas anderes ist als ein Halbleiter. Es gibt aber auch einen Grundpegel, der dann zum Beispiel Werte mit einer Bittiefe von 7 von 128..255 hervorruft, aber auch dass wird natürlich kompensiert. Die Aussage "nicht mehr kompensieren kann" ist davon abhängig, welche minimale Bittiefe je Bildpunkt gefordert ist; denn es macht ja bei bestimmten Anwendungen durchaus Sinn, ein digitales Bild mit einer Bittiefe von 12 haben zu wollen. Deswegen würde ich das achte Bit auch nicht als "niederwertig" betrachten, wenn die Kamera deutlich mehr liefern kann. Für manche Anwendungen wie Webcams oder Smartphone-Kameras mit einer Überausstattung an Bildpunkten mag es ja in Ordnung sein, wenn in manchen Bildpunkten die Bittiefe nur 1 (also dunkel / hell oder 0..1 um in der oben erwähnten Betrachtungsweise zu bleiben) oder noch weniger beträgt, für andere ist das aber nicht akzeptabel. Man denke zum Beispiel an astronomische Aufnahmen, wo ein Stern im Idealfall nur einen einzigen zufälligen Bildpunkt anspricht, bei dem die Fehlertoleranz dann natürlich sehr gering sein muss, um ein brauchbares Bild erhalten zu können.
Die Fehlfunktion von Bildsensorpunkten ist abhängig von der Betriebstemperatur, von der Belichtungsdauer und auch von der Zeit überhaupt (Stichwort "Höhenstrahlung"). Eine einmalige Einmessung ab Werk ist zwar sinnvoll, aber keineswegs optimal.
Eine weitere Frage ist die nach der geometrischen Verteilung der Fehlstellen. Spätestens wenn sich schwache Bildpunkte in einem Bildbereich häufen, was in einem Stehbild kaum zu erkennen sein kann, können diese bei Bewegtbildaufnahmen als störender, im Bild ortsfester Schleier wahrgenommen werden.
Ich will damit eigentlich nur sagen mit "im erlaubten Rahmen" oder "durchschlagen" sind äußerst dehnbare Begriffe, die hier nicht wirklich weiterführen. --Bautsch (Diskussion) 16:21, 22. Okt. 2015 (CEST)
Ich möchte nochmal zurückkehren zu meiner ursprünglichen Kritik:
Gibt es einen Beleg, dass heute (2015) noch immer gilt:
"Bei Kameras mit einer Auflösung von drei Megapixeln und mehr lassen sich CCD-Fehler kaum vermeiden" (sowie nachfolgende Ausführung).
Die erreichbare Fertigungsqualität wächst von Jahr zu Jahr, und was 2008 gegolten hat, gilt heute vielleicht erst ab 12 oder 16 Megapixel.
Kompakte Digitalkamera mit ein- und ausgefahrenem Zoomobjektiv
Benutzer:Smial und Benutzer:SKopp finden das linke Bild "besser" bzw. "technisch und enzyklopädisch wesentlich besser".
Ich stimme zu, dass es schöner ausgeleuchtet ist (inkl. Schatten) und einen schön neutralen Hintergrund hat. Was mir aber auf dem rechten Bild besser gefällt, ist, dass die Kamera speziell beim ausgefahrenen Objektiv aus einem seitlicheren Winkel fotografiert ist - weniger "von vorne". Dadurch sieht man deutlicher, dass ein Zoomobjektiv ganz schön weit aus dem Korpus herausfahren kann. Und das ist, was das Bild zeigen soll. Darum finde ich das rechte Bild besser, um die Aussage darzustellen.
Ich hoffe, lieber Smial, mit dieser Erklärung ist mein Edit jetzt "nachvollziehbar".
3M: Hier muss ich Smial (ausnahmsweise ;-)) Recht geben, das "neue" Bild ist um Einiges schlechter als das "alte" und wenn man nicht zu 99% sehbehindert ist kann darauf auch der beschriebene Effekt wunderbar erkannt werden. Insofern ist deine Änderung für mich auch nicht nachvollziehbar! Es sieht eher nach den ersten Fotografierversuchen eines Anfängers aus, während das alte einen mehr professionellen Eindruck macht. --Dontworry (Diskussion) 09:16, 26. Nov. 2015 (CET)
<quetsch> Ich würde das Bild von Darkone nicht so abqualifizieren, immerhin ist es aus dem Jahr 2004, und wenn du dir den Bildbestand der Wikipedia aus der Zeit anschaust, dann gehört dieses eindeutig zu den "besseren" - und es war ja auch viele Jahre nützlich und gut genug. -- Smial (Diskussion) 15:04, 26. Nov. 2015 (CET)
Man kann auf dem schön-belichteten das ausgefahrene Objektiv schon auch sehen - auf dem anderen aber besser. Und ich finde, das wiegt schwerer als gute Beleuchtung.
Aber wenn den Fotografen hier die Fotokunst wichtiger ist als der thematische Bildinhalt, dann muss wohl das linke Bild in den Artikel.
@Arilou, warum das linke Bild besser ist, hast Du selbst doch schon beschrieben. Es ist nicht nur besser ausgeleuchtet und hat einen neutralen Hintergrund, sondern das Motiv ist auch perspektivisch vernünftig in Szene gesetzt. Und genau das ist bei dem anderen Bild eben nicht der Fall. Hier ist die Kamera stark verzerrt dargestellt. Und deswegen wirkt der Auszug des Objektivs so dramatisch. Das linke Bild ist eben nicht "Fotokunst", sondern vernünftiges Handwerk. Mir ist übrigens auch schon beim Artikel Mazda MX-5 aufgefallen, daß Du einige seltsame Ansichten bezüglich der Fotos zu haben scheinst. Vielleicht solltest Du Deinen Standpunkt in dieser Frage mal überdenken. Ich finde es aber gut, daß Du hier die Diskussion suchst. vg -- Gerd (Diskussion) 09:39, 26. Nov. 2015 (CET)
Beide Bilder sind fast frontal aufgenommen, das rechte ist sogar noch weniger „von der Seite“ (man vergleiche die Beschriftung auf der Seitenfläche der Kamera). Soll es darum gehen, ein möglichst beeindruckendes Ausfahrobjektiv zu zeigen, dann ist vielleicht die gute alte KD-300Z auch einfach nicht das beste Beispiel ;) --SKopp (Diskussion) 10:51, 26. Nov. 2015 (CET)
Nur mal so am Rande: Ich würde in der Bildunterschrift gar nicht von "Zoomobjektiv" sprechen, denn die Zoomfunktion hat damit nichts zu tun. Es geht ja darum, dass das Objektiv in ausgeschaltetem Zustand versenkt ist und um nichts anderes. --Karsten Meyer-Konstanz (D)12:52, 26. Nov. 2015 (CET)
Das ist nicht ganz richtig, weil bei dieser Optik schon ein Unterschied zwischen f=7,8 und 15,6 mm Brennweite erkennbar ist. Bei Kameras mit Festbrennweite ist oft gar kein oder nur sehr wenig Auszug notwendig - u.a. weil beim Fokussieren die Frontlinse nicht verschoben werden muss - und es öffnet sich beim Einschalten nur ein mechanischer Schutz vor der Frontlinse. Dagegen ist bei neueren Kameras mit Superbrennweite (12-fach) der Auszug schon relativ weit im Verhältnis zur Gehäusetiefe. --Dontworry (Diskussion) 15:01, 26. Nov. 2015 (CET)
Das hat trotzdem nichts mit dem Zoomen zu tun, sondern mit der Brennweite. Wenn du zeigen willst, wie sich ein Objektiv bei verschiedenen Zoomstufen äußerlich ändert, dann mach ein Bild davon. DIESES Bild aber soll zeigen, wie ein Objektiv in der Kamera verschwindet. NB: Es gibt Kameras, bei denen das Objektiv mit zunehmender Brennweite kürzer wird - z.B. ist das bei der Panasonic.LX-3 so und sicher auch bei den Nachfolgern. --Karsten Meyer-Konstanz (D)15:37, 26. Nov. 2015 (CET)
Das ist bei der hier abgebildeten KD-300Z auch so. Beide Bilder zeigen sie im voll ausgefahrenen Zustand, der beim Anschalten eingenommen wird, das ist die kürzeste Brennweite von 7,8 mm. --SKopp (Diskussion) 23:24, 26. Nov. 2015 (CET)
Geschichte der Digitalkamera
Letzter Kommentar: vor 10 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
Ich habe heute in einem Forum, in dem ich Angaben bezüglich der ersten Digitalkamera gemacht habe, die aus dieser Seite stammen, folgendes Schreiben erhalten:
Hallo XXX,
muss kurz was klarstellen. Leider sind ALLE Internetquellen die auf die Fairchild verweisen fehlerhaft. Die Fairchild MV-101 war weder die erste kommerziell erhältliche CCD Kamera noch eine Digitalkamera. Irgendjemand aus Amerika hat 2001 oder so eine Seite mit alten Digitalkameras erstellt und somit auch seine Geschichte der Digitalfotografie niedergeschrieben. Leider in vielen Punkten unvollständig und fehlerhaft. Das Problem dabei ist dass es 2001 die erste und einzige umfassende Seite war und seitdem wurde seine Version UND seine Fehler bis in die letzten Winkel des Internets und sogar in Bücher und Zeitschriften weiterkopiert...
Ja, sogar unsere beliebte Kinderbuchreihe "Was ist was" hat diese falschen Informationen in ihre Buchreihe übernommen. Ich habe die schon angeschrieben aber die weigern sich beharrlich die Information aus dem Netz zu nehmen und verdummen weiterhin ihre Leser damit.
Bei 1973 nachlesen... totaler Schwachsinn was da steht. Entschuldigt meine Ausdrucksweise.
Daher bin ich seit 2 Jahren dran dass alles umzuschreiben und endlich meine eigene Seite an den Start zu kriegen.
Wenn man Kodak's Prototypen von 1975 mal ignoriert und mit der Fuji DS-1P die erste Konsumenten Digitalkamera 1988 auf den japanischen Markt kam so sind das gerade mal 25 Jahre... ABER angesichts der rasanten Entwicklungen und Fortschritte in Speicher- und Sensortechnik kann man bei den Digitalkameras bis etwa 1994/1995 schon von Oldtimern oder Urgesteinen sprechen.
"Bayer-Sensoren haben keine Subpixel."
~ Quatsch. Direkt das Einleitungs-Bild im Artikel Bayer-Sensor zeigt die Bayer-Matrix mit roten, grünen und blauen Subpixeln. (Zitat: "[..] wird vor jeder einzelnen Zelle ein winziger Farbfilter in einer der drei Grundfarben Rot, Grün oder Blau aufgebracht.")
"Da werden keine "Subpixel" "gewichtet" "zusammengefaßt"."
Subpixel - tja.
Größe der Subpixel (laut Bayer-Sensor) i.A. 50% grün, 25% rot, 25% blau. Zusätzlich: "Für Grün werden somit 50 % der Pixel errechnet, bei Blau und Rot sind es jeweils 75 % der Fläche (oder in einer Zeile 50 % und in der Folgezeile 100 % der Zeile), die durch Berechnung gefüllt werden müssen.)" Farbwerte werden also aus umliegenden Subpixeln errechnet (ein mathematisches "'Zusammenfassen"), und dabei ggf. gewichtet (das kann auch eine Gleich-Gewichtung sein).
Fazit: Anmerkung ist ebenfalls falsch.
Sorry lieber Smial, da blieb mir nur ein voller Revert.
PS: Der Artikel ist/war insgesamt in einem Zustand, als ob er seit 5-10 Jahren nicht mehr überarbeitet wurde. Außerdem scheint er von (Analog-)Fotografen geschrieben, mit - sagen wir mal - beschränkter Kenntnis der Technik. Einleitung und die oberen Kapitel hab' ich mittlerweile etwas überarbeitet, die unteren Kapitel schau' ich mir auch noch an.
Die Sache mit den Subpixeln ist grober Unfug, das "Zusammenfassen" impliziert, daß aus den "Sub"-Pixeln durch irgendein Zauberwerk erst die eigentlichen Pixel entstehen würden. Das wären dann Suppixel? Ein Bayer-Sensor hat keine Subpixel. Und es findet kein "Zusammenfassen" statt, sondern aus je vier Pixeln RGGB werden tatsächlich wieder vier Pixel errechnet, jeweils mit dem vollen RGB Farbraum. Die Verfahren sind dabei durchaus komplex und mit "gewichtetem Zusammenfassen" äußerst unzureichend verkürzt beschrieben. Nicht von ungefähr passieren bei der Bayer-Raterei oft genug lustige Artefakte, wie z.B. die berüchtigten Sägezähne bei Kanten mit hohem Kontrast und "falschen" Farbübergängen bei feinen Details, dummerweise und sehr häufig ausgerechnet (und naheliegenderweise) bei Aufnahmen mit sehr hochwertigen aka scharf zeichnenden Objektiven. Aber bleib du mal ruhig bei deinen erfundenen "Sub"pixeln. Canon-Fotograf? Die haben iirc den Begriff für ihre Kameradisplays eingeführt, womit die plötzlich mit 900.000 "Subpixeln" Auflösung werben konnten, während die Konkurrenz noch bei erbärmlichen 300.000 herumhampelte. Für dasselbe Display... -- Smial (Diskussion) 10:11, 22. Okt. 2015 (CEST)
„das "Zusammenfassen" impliziert, daß aus den "Sub"-Pixeln durch irgendein Zauberwerk erst die eigentlichen Pixel entstehen würden.“ JA, GENAU SO IST ES: Ein einzelnes (Sub)Pixel kann aufgrund des vorgeschalteten Farbfilters nur "seine Farbe" erfassen. Es ist also ganz sicher kein "vollwertiges" Pixel. Erst durch (mehr oder weniger) komplexes -hm- "Zusammenfassen/-rechnen-/..." werden daraus Vollfarb-Pixel, und mitunter entsteht erst durch dieses "Zauberwerk" die x-y-Anordnung für das Bild - die (Sub-)Pixel-Matrix kann z.B. sechseckig angeordnet sein, beim Super-CCD-Sensor ist die CCD-Zeile um 45° gedreht, ggf. sind neben RGB noch weitere Subpixel (Cyan, Magenta, Gelb) vorhanden, ...
"aus je vier Pixeln RGGB werden tatsächlich wieder vier Pixel errechnet, jeweils mit dem vollen RGB Farbraum." Die 'RGGB'-Pixel werden Subpixel genannt, um sie von den errechneten 'vollen-RGB-Farbraum-Pixeln' unterscheiden zu können. Mann mann mann, mehr ist an der "Subpixel-Sache" doch gar nicht dran...
"deinen erfundenen "Sub"pixeln" - die Artikel Subpixel, Subpixel-Rendering habe ich weder erstellt noch jemals editiert (soweit ich mich erinnere); Super-CCD-Sensor spricht von "Sensorelement", "Sensorpixel", wie auch immer.
"Canon" - heute werben so ziemlich alle Hersteller mit der Anzahl der (einfarbigen) Sensorelemente ("Subpixel").
Wie du jetzt auf Suppixel kommst, ist mir unverständlich.
Das 'Sub' des Begriffs Subpixel wird manchmal (schludrigerweise) weggelassen, wenn eindeutig ist, dass gerade nicht von der 'Obereinheit' "Vollfarb-Pixel" die Rede ist, sondern von einem einfarbigen (R, G oder B) Subpixel.
"Subpixel" ist also die 'Untereinheit' von "Vollfarbpixel" - man braucht (mindestens) 3 Subpixel (R,G,B), um einen Vollfarb-Pixel berechnen zu können.
PS: Ich lass' Specials jetzt mal außen vor à la "weitere Subpixel-Farben neben R,G,B", "verschiedenes Zusammenfassen" oder Abwägungen, wie "vollwertig/vollfarbig" ein Vollfarb-Pixel tatsächlich ist.
"man braucht (mindestens) 3 Subpixel (R,G,B), um einen Vollfarb-Pixel berechnen zu können." Wenn das dein Wissensstand bezüglich digitaler Bildaufnehmer mit Bayer-Filter ist und dein ganzes agressives Auftreten hier auf selbigem basiert, sollten wir die Diskussion schleunigst beenden und ich rate dir, die zugehörige Literatur nicht nur zu lesen, sondern dich auch zu bemühen, sie zu verstehen. Ist ja unfaßbar. "Ich lass' Specials jetzt mal außen vor à la [...] "verschiedenes Zusammenfassen" oder Abwägungen, wie "vollwertig/vollfarbig" ein Vollfarb-Pixel tatsächlich ist." Genau das muß du latürnich außen vor lassen, wenn du den Begriff "Subpixel" bei Bayersensoren auf die dir genehme, wenn auch unsinnige Weise einführen möchtest. -- Smial (Diskussion) 15:52, 30. Nov. 2015 (CET)
Im Prinzip ist's ganz einfach: Subpixel sind die real vorhandenen Sensorflächen; ein solcher Subpixel kann (z.B. aufgrund vorgeschaltetem Farbfilter) nur Rot (oder nur Grün, oder nur Blau) wahrnehmen. Außerdem können die Subpixel verschieden groß sein, nicht-rechteckig, nicht-rechteckig angeordnet, es kann auch noch Gelb-empfindliche geben, ... - was auch immer die Hersteller der Sensorchips für sinnvoll erachten.
Später im Bild (.jpg, .png, .sonstwas, ggf. auch bereits im Kamera-Raw-Format) gibt es nur noch quadratische, quadratisch angeordnete Vollfarb-Pixel; diese können je nach Bildformat in verschiedenen Farbsystemen angegeben sein - .jpg braucht z.B. Chroma-Luma-Informationen, da geht 'RGB' nicht.
Und ich denke, es ist offensichtlich, dass man aus einem einzelnen Rot-Subpixel kein Vollfarb-Pixel errechnen kann. Dafür braucht man zusätzlich die Informationen der danebenliegenden Grün- und Blau-Subpixel.
Ach ja: Den Begriff "Subpixel" habe nicht ich eingeführt. Er wird verwendet in vielen Veröffentlichungen, auch wenn du dich noch so sehr dagegen streubst.
Siehst Du nun die anliegenden Punkte R,B, tatsächlich als Subpixel eines übergeordneten Pixels? Dir ist schon bewusst, dass die nichts mit einander zu tun haben müssen, -> Aberation. 80.146.181.12316:02, 10. Dez. 2015 (CET)
Gerade weil die physikalisch vorhandenen Hardware-Sensorelementchen u.U. keinen direkten/1:1- Bezug zu den Vollfarb-(Software-)Punkten der schlussendlich gespeicherten Bilddatei haben, ist es notwendig, sie auch sprachlich abgrenzen zu können. Daher nennt man sie "Subpixel"...
Der Name ist aus der anfänglichen Vorgehensweise entstanden, dass (zu Beginn der Digitalbildkameras) einfach drei R-, G- und B-Subpixel zu einem Vollfarb-Bildpixel zusammengefasst wurden.
3M: Wenn ich die (online vorhandene) Literatur überfliege, wird mir schnell klar, dass der Begriff "Subpixel" in der der von Arilou verwendeten Bedeutung existiert, siehe z.B. hier. Ich kannte den Begriff vorher auch nicht - wieder was gelernt. Weihnachtliche Grüße, Darian (Diskussion) 17:37, 24. Dez. 2015 (CET)
3M: Der Begriff "Subpixel" wird zwar gerne hier und da mangels sprachlicher Alternative verwendet, widerspricht aber vollkommen der eigentlichen Pixel-Definition, wie auch Benutzer Smial treffend bemerkt. Insofern TF und die WP sollte hier erstmal höchst zurückhaltend agieren.
Vorschlag: Die Definition von Pixel in der Einleitung zu einem einzelnen grünen "Sub"-Pixel klar abgrenzen. Belege beibringen. Ggf. gibt es ja Quellen, die zeigen, wie die technische Weiterentwicklung den weltweit bekannten, standardisierten monochromen Pixel über die Jahre "umdefiniert" hat. Ein einzelner Link, gar vom Fachmagazin "Stiftung Warentest" reicht bei diesem Thema bei Weitem nicht. Ich erwarte hunderte von Links aus dem Milliardenmarkt.
Bitte zu bedenken, dass sich Pixel (schon immer) zu farbigen Flächen zusamensetzen. Farbige Flächen zu Linien. Linien zu Bildern. Bildern zu Filmen. Dass es dabei zu den angesprochenen Kanten-, Alias- und sonstige Interpolationsproblemen kommt, ist kein Wunder. Der vermeintliche "Subpixel" ist weder Ursache noch Lösung, er ist einfach nicht existent. --Wunschpunkt (Diskussion) 22:26, 18. Jan. 2016 (CET)
Hardwaremäßig besteht ein Pixel bei einem Bayer-Sensor aus einem blauen, einem roten sowie zwei grünen Subpixel. Dass die Software jedes Subpixel als eigenes Pixel behandelt und für die anderen Farben die Werte aus benachbarten Subpixeln interpoliert ändert daran nichts. --MrBurns (Diskussion) 13:06, 19. Jan. 2016 (CET)
Hast Du dafür auch einen Beleg? Wissen da immer genau 4 "Subpixel", dass sie zusammengehören? Wer sagt ihnen, welche Nachbarn zum eigenen Pixel gehören und welche zum Nachbarpixel? MBxd1 (Diskussion) 20:03, 19. Jan. 2016 (CET)
GBRG-Anordnung mit 16x10 Subpixel4 quadratisch angeordnete Subpixel ist die kleinste sich wiederholende Subpixelanordnung beim Standard Bayer-Sensor, es gibt üblicherweise genau eine Möglichkeit diese so zu gruppieren, dass es am Rand keine Abweichungen gibt: man fangt mit einem Quadrat in irgendeinem Eck an, der Rest ergibt sich dann von selbst (das trifft zu, falls die vertikale und horizontale Subpixelzahl jeweils gerade sind, ansonsten gibt es gar keine Möglichkeit dazu). Je nachdem, welches Pixel links oben ist, hat man dann die Anordnung RGGB, BGGR oder GBRG. Letztere Anordnung wird im Beispiel-Bild im Artikel Bayer-Sensor verwendet. Diese Definition eines Pixels ist analog zu der bei Displays, nur dass bei Displays ein Pixel halt üblicherweise nur 3 Subpixel hat und diese anders angeordnet sind. Bei einem LC-Display, das die Farben wie bei einer Streifenmaske angeordnet hat, kann man auch argumentieren, dass es willkürlich ist, ob man beim zusammenfassen von jeweils 3 Streifen zu einem Pixel mit einem roten, grünen oder blauen anfangt (es gibt aber auch Displays mit 4 Subpixel und der gleichen Anordnung wie bei einem Bayer-Sensor, jedenfalls in Patent-Zeichnungen[1], tatsächlich üblich ist da aber eher eine Anordnung, bei der die grünen Pixel kleiner sind, wie hier bei dem Bild wo 13/14 steht). Und es gibt durchaus Quellen, die das Wort Subpixel im Zusammenhang mit Bayer-Sensoren verwenden. z.B. [2] --MrBurns (Diskussion) 22:32, 19. Jan. 2016 (CET)
Das entspricht so auch meinem Kenntnisstand: Es gibt keine Pixel, zu denen sich die "Subpixel" fest definiert zusammenfügen würden. Diese "Großpixel" sind eine rein theoretische und variable Konstruktion, sie existieren nicht wirklich. Tja, und damit existieren nur die "Subpixel" wirklich, weswegen man sie auch einfach als Pixel bezeichnet, da es ja eh keine anderen gibt. MBxd1 (Diskussion) 22:59, 19. Jan. 2016 (CET)
Man könnte ein Pixel definieren als die kleinste sich wiederholende Anordnung von Subpixeln, aus denen sich der gesamte Sensor aufbauen lässt. Diese Definition wäre sinnvolle, einheitlich und mit der Definition bei Displays konsistent, wenn die vertikale und horizontale Subpixelzahl jeweils gerade sind. In dem Beispielbild entspricht das dem, dass man die Subpixel mit den Koordinaten (0,0),(0,1),(1,0) und (1,1) zu einem Pixel zusammenfasst, die anderen 2x2-Gruppen ergeben sich dann von selbst. Das Ergebnis ist dasselbe wenn man in einem anderen Eck beginnt, also z.B. bei (14,9),(14,10),(15,9) und (15,10). --MrBurns (Diskussion) 23:34, 19. Jan. 2016 (CET)
Es ist völlig klar und unstrittig, dass man das könnte, und auch, dass man das so machen würde. Nur bleibt das eine theoretische Konstruktion. Es gibt eben in der Hardware nichts, was diese Pixel zusammenfassen würde. Und da Sensoren immer auch ungenutzte Randflächen haben, ist es auch nicht notwendig, in der mit einem kompletten "Großpixel" anzufangen. Die Zusammenfassung der "Subpixel ist beliebig, und bei der Auswertung werden sowieso alle Nachbar-"Subpixel" herangezogen. Unterschiedslos. Es gibt nichts, was die vermeintlich zum selben "Großpixel" gehörenden "Subpixel" von ihren Nachbarn auf der anderen Seite unterscheiden würde. Diese "Großpixel" (Du nennst sie "Pixel") sind eine rein fiktive Konstruktion. Ganz im Gegensatz zu den "Subpixeln", die real in der Hardware existieren - weswegen man sie siewöhnlich Pixel nennt. MBxd1 (Diskussion) 23:43, 19. Jan. 2016 (CET)
Dein Argument könnte man aber auch z.B. bei allen Farb-Displays mit fixer Pixelanordnung anwenden (z.B. Farb-LCDs). Dennoch spricht man dort von Pixeln, die aus jeweils 3 (in manchen Fällen auch 4, z.B. bei OLED gibts 4-Subpixel-Anordnungen) Subpixeln bestehen. --MrBurns (Diskussion) 23:46, 19. Jan. 2016 (CET)
Es geht nicht darum, was man wo anwenden könnte, es geht um die reale Benennungspraxis. Und da werden die Pixel eines Bayer-Sensors eben als Pixel bezeichnet und nicht als Subpixel. MBxd1 (Diskussion) 20:50, 20. Jan. 2016 (CET)
Bei einem derart gängigen Thema sind einzelne Fälle von abweichender Wortwahl durchaus denkbar - nur eben nicht wirklich von Bedeutung. MBxd1 (Diskussion) 23:17, 20. Jan. 2016 (CET)
In Hardware existieren nur die "Subpixel", soweit stimme ich zu. Sofern klar ist, dass man im aktuellen Kontext ausschließlich über diese Sensorflächen spricht, kann man sie auch einfach "Pixel" nennen, dann gibt's ja keine Notwendigkeit einer Abgrenzung. Das interessiert aber - außer den Sensor-/Kamerahersteller - praktisch niemanden. Den Fotograf interessiert beim Fotografieren, was er als (Software-)Bild auf seinen PC überspielen, bearbeiten, weitergeben, ausdrucken kann.
In Software kann es sowohl eine 1:1 -Entsprechung zur Hardware geben (manchmal ist das das Kamera-Raw-Format), als auch Bildformate, bei denen (wie auch immer) die Daten der Hardware-(Sub-)Pixel in "Pixel" des (Software-)Bildformats umgerechnet werden. In den Software-Formaten ist ein Vollfarb-Pixel ein 3-Tupel (R;G;B) - fast immer quadratisch, praktisch immer in Zeilen und Spalten rechteckig angeordnet.
Ach ja - was ein WP-Autor als "von Bedeutung" betrachtet oder nicht, ist POV. Wenn der Begriff von (halbwegs) anerkannter Stelle verwendet wird, ist er gebräuchlich.
+1 Wh: Der Begriff "Subpixel" wird zwar gerne hier und da mangels sprachlicher Alternative verwendet, widerspricht aber vollkommen der eigentlichen Pixel-Definition, wie auch Benutzer:Smial treffend bemerkt. Insofern WP:TF und die WP sollte hier erstmal höchst zurückhaltend agieren. --Wunschpunkt (Diskussion) 22:40, 26. Feb. 2016 (CET)
@MBxd1: Eine im Alltag, in Allgemein- und Fachliteratur auftretende Benennung ist auch dann in der WP aufzuführen, wenn sie nur von einer Minderheit verwendet wird (was sowieso bisher nur eine Behauptung ist). Andere Meinungen und Sprachgebrauche als "Außenseiternomenklatur" unterdrücken und abweisen zu wollen, ist nicht im Sinne einer offenen Wikipedia.
Du hast oben "Schludrigkeit" unterstellt, wenn man beim "Subpixel" das "Sub" weglässt. Also bist Du es, der eine bestehende Nomenklatur nicht akzeptiert. Selbstverständlich folgen wir hier dem üblichen Sprachgebrauch und werden nicht aus Proporzgründen zwischen verschiedenen Begriffen hin- und herhüpfen. Das wäre für den Leser nämlich nicht mehr nachvollziehbar. MBxd1 (Diskussion) 21:02, 29. Feb. 2016 (CET)
3M: Es gibt natürlich "Subpixel" - genau dann, wenn tatsächliche Pixel aufgeteilt werden. Bspw. beim Dithering kann die zeitliche Schwankung pixelgenauer Information durch Korrelation mit dem optischen Fluss zu subpixelgenauer Information hochgerechnet werden - so als ob ein Pixel tatsächlich aus mehreren bestünde und der Sensor eine höhere Pixelanzahl hätte. Auch in einer einfachen Betrachtung der Farbanalyse (Bayer Matrix) und Farbsynthese (Display) erscheint das Bild eines Farbpixels, das aus 4 farbigen Subpixeln besteht, zunächst plausibel. Daher wird diese Darstellung gerne und fälschlicherweise auch in vielen populärwissenschaftlichen Darstellungen und im Schulunterricht vermittelt. Dass in realer Technik beim Debayern der berechnete Farbwert des Pixels aus mehr oder weniger Nachbarn ermittelt wird und bei der Synthese die Farbwerte der mehr oder weniger nahen Pixel anhand des darzustellenden Farbwerts errechnet wird. spricht gegen die Darstellung der Bayer-Matrix als Subpixel. Insbesondere, da je nach Debayering-Methode auch gerne mal 4 einfarbige Pixel zu 4 farbigen Pixeln transformiert werden können. "Subpixel" - eindeutig ja, im Kontext von Bayer-Matrix und Displaytechnik aber zweischneifdig und daher IMHO möglichst vermeiden. Besser sind hier IMHO die Begriffe "einfarbiges Pixel" und "Farbpixel".--Alturand (Diskussion) 15:17, 4. Mär. 2016 (CET)
Wie man "debayerd" ist doch eine reine Softwarefrage. Man könnte auch einfach für ein grünes Subpixel am nur Monitor zwei grüne Bayer-Flächen verwenden, für ein rotes Subpixel eine rote Byer-Fläche und für ein blaues eine blaue Bayer-Fläche. Dann hätte man auch Softwaremäßig ein Bayer-Pixel, das aus einem blauen, einem roten und zwei grünen Subpixeln besteht. man macht das aber nicht, weil man damit die halbe Auflösung und 174 der Pixelzahl hat im Vergleich dazu, wenn man jeder Bayer-Fläche ein vollfarb-Pixel zuordnet. Natürlich gäbe es auch bei der erstgenannten Methode Artefakte dadurch, dass die Anordnung der Pixel am Bayer-Sensor nicht der der Subpixel am Monitor entspricht (bzw. da es verschiedene mögliche Subpixelanordnungen bei Monitoren gibt und bei Grafiken normalerweise kein Subpixel-Rendering durchgeführt wird, nimmt man an, dass am Monitor alle Subpixel an der gleichen Stelle sind), aber diese Artefakte wären nur bei enormer Vergrößerung wirklich sichtbar, da sie ja nur auf Subpixel-Ebene auftreten. Dafür gibt es in der Grafik keine "erfundenen" (genauer gesagt interpolierten) Subpixel, die es bei der üblichen Methode gibt und die zu viel schlimmeren Artefakten führen können. --MrBurns (Diskussion) 21:02, 4. Mär. 2016 (CET)
"Elektronischer Sucher"
Letzter Kommentar: vor 7 Jahren3 Kommentare2 Personen sind an der Diskussion beteiligt
me3ines Wissens ist die Erklärung des Begriffs "Elektronischer Sucher" im Artikel inkorrekt: wenn nur das Objektivbild am Hauptdisplay der Kamera angezeigt wird, ist das kein elektronischer Sucher (wird üblicherweise auch nicht als ein solcher beworben), sondern ein Display mit Live-View. Ein elektronischer Sucher ist ein kleines zusätzliches Display zum Reinschuaen mit einem auge und schaut auf den ersten blick von der Rückseite gesehen wie ein herkömmlicher Sucher aus. --MrBurns (Diskussion) 05:40, 17. Mär. 2017 (CET)
Stimmt im Prinzip. Mir war aber im Artikel keine fehlerhafte Verwendung aufgefallen. Wenn Du eine findest, korrigier sie doch einfach. MBxd1 (Diskussion) 13:18, 17. Mär. 2017 (CET)
Folgender Satz ist jedenfalls missverständlich:
Die Anzeige erfolgt auf einem auf der Kamerarückseite angebrachten Display, zusätzlich kann ein zweiter Kleinst-Monitor im Gehäuse integriert sein, der mit einem herkömmlichen Suchereinblick kombiniert ist.
Abschnitt "Foto-Auflösung verringern um Bildqualität und Performance zu erhöhen"
Letzter Kommentar: vor 6 Jahren3 Kommentare2 Personen sind an der Diskussion beteiligt
Ich wäre dafür, diesen ganzen Abschnitt zu löschen, weil ich (heute!) niemand dazu raten würde. 2013 (von da stammt der Tipp der Stiftung Warentest) war das vielleicht noch anders, heute mag es nur noch für Smartphones mit absurd hohen Pixelzahlen bei gleichzeitig wenig Speicher sinnvoll sein. Abgesehen davon ist das nichts, was man nicht hinterher auch noch machen könnte. Und gibt es eigentlich eine einzige Kamera, das bei Einstellung auf eine kleinere Auflösung auch darauf angepasste Rohdaten liefert? --Karsten Meyer-Konstanz (D)10:58, 5. Dez. 2017 (CET)
Zitat: "heute mag es nur noch für Smartphones ... sinnvoll sein"
Sobald Du uns Deine Quelle nennst, können wir sie gerne den bisherigen Quellen gegenüberstellen. -- ηeonZERO13:53, 5. Dez. 2017 (CET)
Zitat: "Und gibt es eigentlich eine einzige Kamera, das bei Einstellung auf eine kleinere Auflösung auch darauf angepasste Rohdaten liefert?"
Auf die Schnelle habe ich ebenfalls keine Kamera gefunden, die das von Haus aus kann. Daher habe ich den Satz entsprechend angepaßt. Danke für den Hinweis. -- ηeonZERO14:20, 5. Dez. 2017 (CET)
Pixel und Subpixel
Letzter Kommentar: vor 8 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
Bitte entschuldigt zunächst, dass ich einen neuen Abschnitt starte. Leider ist eure Diskussion und die Argumente sehr unübersichtlich geworden. Vielleicht kann es helfen, wenn ich meine Meinung dazu zusammenfasse. Dazu sei angemerkt, dass ich aus der Informatik komme (30 Jahre Softwareentwicklung, davon 20 Jahre professionell; Computergrafik ist eines meiner Lieblingsthemen).
Der Begriff Pixel ist scheinbar wohlbekannt - hier kann ich keine Deutungsprobleme erkennen.
Der Begriff Subpixel wird unzweifelhaft in verschiedenen Anwendungsgebieten verwendet - allerdings scheint mir der Kern eurer Diskussion zu sein, wann genau bzw. was er genau bedeutet.
Als Informatiker sehe ich Pixel als abstrakten Begriff, der nicht notwendigerweise an Hard- oder Software gebunden ist. Da es letztendlich um Digitaltechnik geht (und am Ende ein digitales Modell eines Bildes erwartet wird), scheint mir eine Unterscheidung in physische und logische Pixel unnötig bzw. sogar irreführend. Ob die Pixelinformation in einem speziellen Hardwarebaustein erzeugt / gehalten oder in einem abstrakten Model im Speicher gehalten werden, ist für die Anwendung irrelevant.
Klassischerweise haben die Hardwareelemente mehr oder weniger starke Einschränkungen - normalerweise können sie nur die Intensität von Licht einer bestimmten Wellenlänge messen (bzw. beim Monitor: emittieren).
Die Anordnung dieser Hardwareelemente ist natürlich unterschiedlich und von der konkreten Technologie abhängig (siehe z.B. Pixel geometry).
Die erhobenen Informationen werden in mehreren Stufen mit diversen Matrizen weiterverarbeitet. Bis zur Darstellung auf dem Ausgabemedium wird die Struktur der Pixelinformationen mehrfach geändert als auch deren konkrete Werte mehrfach umgerechnet - dies geschieht für einzelne Pixel, für Pixelgruppen, als auch für das gesamte Bild. In der laienhaften Sicht des Informatikers z.B.:
Anregung eines bestimmten Hardwareelements (eines eng begrenzten Wellenlängenbereiches)
Korrekturfilterung um Nicht-Linearität der Hardwareelemente auszugleichen
Gewichtung benachbarter Elemente zur Schärfeverbesserung (unter Berücksichtigung der Geometrie der Hardwarelemente)
Kombination verschiedener Hardwareelemente zu einem Farbpixel
Normalisierung und Weißabgleich der Bildinformationen
Umwandlung von HDR-Bildinformationen in 32-bit True Color Pixelwerte (oder noch Schlimmeres)
Hinzufügen eines Alphakanals für die digitale Bildbearbeitung
(Farb-)Kanaltrennung und -rekombination im Grafikprogramm
Umwandlung vom RGB- in HSV-Informationen im Grafikprogramm
Anwendung diverser fotografischer oder künstlerischer Filter (in Software)
Komprimierung der Bilddaten zur dauerhaften Speicherung
Umwandlung von RGBA- + Z- in RGB-Informationen in OpenGL
Umwandlung von RGB- in CMYK-Informationen (oder noch exotischer) im Druckertreiber
Farbkorrektur zur Anpassung an die Nicht-Linearität der Ausgabeelemente (z.B. Drucker oder Monitor)
Dithering der Bildinformationen mit verschiedensten Algorithmen im Drucker oder Druckertreiber
Umwandlung von Bildinformationen in Steuerungcodes zur Anregung der Ausgabeelemente (z.B. Düsen im Tintenstrahldrucker)
... (viele, viele mehr)
Alle diese Vorgänge haben Ein- und Ausgabeformate, manchmal sind die Formate gleich, manchmal werden Informationen reduziert, manchmal neue hinzugefügt; mit jedem Arbeitsschritt tritt jedoch immer eine Bedeutungsänderung der Pixelinformationen ein (z.B. nicht-normalisierte in normalisierte Pixel).
Das für mich einzig Entscheidende ist allerdings der Anwendungsfall bzw. der Standpunkt des Betrachters - und der ist natürlich vollkommen subjektiv:
Für den Endverbraucher, der einen Monitor kauft, ist einzig und allein ein farbiger Ausgabepixel relevant - der Z-Buffer seiner 3D-Karte interessiert ihn nicht
Der Ingenieur, der das Dithering im Drucker(treiber) implementiert, erzeugt aus wenigen Eingabepixeln viele Ausgabepixel
Der Konstrukteur, der eine CCD-Matrix entwirft, interessiert sich möglicherweise herzlich wenig für die daraus entstehenden klassischen RGB-Farbpixel
Ein Entwickler eines Raytracers verwendet Supersampling, um aus vielen Intensitätspixeln wenige (schärfere) Intensitätspixel zu erzeugen (in OpenGL werden daraus sogar noch RGBAZ-Pixel)
Fasst man nun das Präfix Sub im Sinne von Feinstrukturierung auf, ergeben sich letztendlich aus der Sicht aller dieser Vorgänge unterschiedliche Definitionen für Pixel und Subpixel (und eigentlich auch Superpixel):
Pixel ist jenes Bildelement, mit dem der Prozess in seinem Modell arbeitet
Subpixel sind (falls vorhanden) jene feineren Bildelemente, die vor- oder nachgelagerte Prozesse verwenden
Superpixel sind (falls vorhanden) jene gröberen Bildelemente, die vor- oder nachgelagerte Prozesse verwenden
Der Entwickler des Raytracers arbeitet allgemein auf der Ebene von Intensitätspixeln; setzt er Supersampling ein, bezeichnet er die Feinstruktur als Subpixel - in seiner Welt (und vor allem in der Kommunikation mit seinen Fachkollegen) macht das vollkommen Sinn.
Konkretisiert auf das Thema Digitalfotografie: da sich die Enzyklopädie nun an inhaltlich Unerfahrene richtet, macht es meiner Meinung nach nur Sinn, das Thema aus deren Sichtwinkel bzw. Anwendungsfall zu betrachten. Er interessiert sich für die tatsächlichen Farbpixel, die er erhält (was auch immer er damit danach noch tun will) - was im Inneren der Maschine passiert, hat ihn (bisher) nicht interessiert. Demnach würde er die einfarbigen Pixel der tatsächlichen Hardwareelemente wohl sofort als Subpixel verstehen. Auch als Informatiker, verstehe ich den Begriff so (ohne wirklich zu verstehen, was ein Bayer-Sensor ist).
Natürlich kann der Hersteller aus seiner Sicht argumentieren, die einfarbigen Pixel seien die wahren Pixel und deren Auflösung angeben. Allerdings wäre das am Nutzungsfall vorbei und meiner Meinung nach eine Verbrauchertäuschung, wenn es nicht ausreichend kommuniziert wäre. Das wäre ähnlich dem Verhalten von Festplattenherstellern, die irgendwann anfingen, Mega als 10^6 zu definieren (statt 2^20 wie bisher).
--Chronomancer (Diskussion) 06:09, 5. Mär. 2016 (CET)
Vielen Dank für die umfassende Ausarbeitung, Chronomancer. Nach meiner Erinnerung kam der Begriff "Subpixel" in der Werbung für Digitalkameras auf, als die Marketingleute der Kamerahersteller auf die glorreiche Idee kamen, bei der Auflösung der Displays die einfarbigen Pixel anzugeben und dadurch eine dreifach höhere Auflösung vortäuschten. Dies im Gegensatz zu den damals schon lange gebräuchlichen Angaben bei Flachbildschirmen im Computerbereich. Ich kann mich erinnern, selbt mehrere Test-Instituionen auf diesen Widerspruch hingewiesen zu haben. Daraufhin verwendete dann jemand den Begriff Subpixel, um auf den Unterschied zur anderswo gebräuchlichen Angabe der Farbpisel zu hinzuweisen.
53cm?
Letzter Kommentar: vor 4 Jahren2 Kommentare2 Personen sind an der Diskussion beteiligt
"Die Elektronik und der Kassettenrekorder waren in einem 53 cm Geräteschrank eingebaut" - wird das nicht eher ein 19"-Rack (oder Schrank) gewesen sein? ETSI werden sie dort in US zu der Zeit wohl eher nicht verwendet haben, außerdem wäre das dann 53,5 cm. Ich kenne keinen "53-cm-Standard", aber die Formulierung legt nahe, es gäbe einen solchen. --Smial (Diskussion) 12:53, 24. Nov. 2018 (CET)
Ein 19"-Rack hat aber auch nicht 53cm, sondern 48,26 cm. Daher vermute ich, dass ein ETSI-Schrank gemeint ist und die 53,5 cm einfach abgerundet wurden. Es kann sich aber natürlich auch um eine Fehlinformation handeln. --MrBurns (Diskussion) 15:08, 13. Jan. 2020 (CET)
Verständnisfragen zur Auflösung in lp/mm
Letzter Kommentar: vor 4 Jahren51 Kommentare3 Personen sind an der Diskussion beteiligt
Die Pixelgröße eines Bildsensors im Verhältnis zur maximalen Auflösung in lp/mm
Hochauflösende Diafilme der analogen Fotografie, wie beispielsweise der Fuji Velvia 50, geben laut Hersteller die Leistung des Films unter idealen Kontrastbedingungen mit 160 Zeilen (80 Linienpaare) pro Millimeter an; eine digitale Kamera bräuchte einen Kleinbild-Vollformat-Sensor mit 87 Megapixeln, um an diese Auflösung heranzukommen.[1]
Daraus ergeben sich die folgenden Werte, die zur Überprüfung der Aussage herangezogen werden können: Bei einem für Kleinbild-Vollformat-Sensoren typischen Seitenverhältnis von 3:2 entsprechen 87 Megapixel einer Auflösung von 11424x7616 Pixeln.[2] Bei einer 1.7047 Zoll Sensorsdiagonale (das entspricht 43,3mm eines typischen KB-Sensors) ergibt sich eine Pixelgröße von 3,15 µm[3] (in Höhe und Breite). Die Formel für Lienenpaare kommt mit diesen Daten auf 79,36 lp/mm,[4] was die Aussage der ersten Quelle stützt.
So weit, so gut. Wie aber ist es möglich, dass ein Kleinbild-Vollformat-Sensor mit gerade einmal 61 Megapixeln im Testlabor auf deutilch über 100 lp/mm kommen kann?[5] Nach Berechnung gemäß der obigen Quellen liegt die Pixelgröße des Sensors in Höhe und Breite bei 3,75 µm[3] (9600x6400 Pixel). Mehr als 67 lp/mm sollten mit diesem Farbsensor nicht erfasst werden können (500 / (3,75µm * 2) = 500 / 7,5 = 66,66 lp/mm).[4] Das als Quelle 5 genannte Testlabor ist nicht das Einzige, dass im Ergebnis deutlich höhere Auflösungswerte ermittelt. Aber wie kann das sein? Entweder sind die Berechnungen aus den ersten vier Quellen falsch oder die Testergebnisse liegen daneben (was eher unwahrscheinlich ist) oder ich verstehe etwas nicht richtig. -- ηeonZERO20:46, 23. Dez. 2019 (CET)
↑ abÜbereinstimmend mit Sensorberechnungen auf vision-doctor.com zur Berechnung der Pixelgröße in µm (mit Nachkommastellen) sowie Pixelgrößen Rechner auf lcdtech.info als zweite Referenz (ohne Nachkommastelle, dafür mit MP-Berechnung)
↑ abFormel für Farbsensoren: Linienpaare = 500 / (Pixelgröße in µm * 2); Formel für Monochromsensoren: Linienpaare = 500 / (Pixelgröße in µm * 1,41) gemäß OptoWiki
↑Testbericht: Sony Alpha 7R IV, digitalkamera.de, Seite 2, 15.11.2019, getestet am Objektiv „Sony FE 35 mm F1,8“ und „Sony FE 24-105 mm F4 G OSS“, Autor: Benjamin Kirchheim
Bei einem Bildsensor im Kleinbildformat mit 67 Millionen Bildpunkten ist der Abstand der Bildmittelpunkte mit 5,3 Mikrometern so groß wie der Durchmesser eines Beugungsscheibchens, das bei einem Objektiv mit der Blendenzahl 4 erzeugt wird. Bei größeren Blendenzahlen ist der Durchmesser der Beugungsscheibchen größer. Davon völlig unabhängig ergeben sich durch verschiedene Abbildungsfehler Auflösungsbegrenzungen, die mit kleinerer Blendenzahl und zu den Bildecken hin zunehmen. Ein sehr gut korrigiertes Objektiv für eine Kleinbildkamera hat auf der optischen Achse keine Aberrationen, die die optische Auflösung begrenzen.
Der Kontrast ergibt sich aus einem Verhältnis der Helligkeiten zweier benachbarten Punkte. In einem perfekten Bild ist dieser genauso groß, wie beim aufgenommen Original, und das Verhältnis dieser beiden Kontraste ist demzufolge eins (anders ausgedrückt: die Kontrastübertragung beträgt 100 Prozent).
Kontrastempfindlichkeitsfunktion des menschlichen AugesBeispiel zur Veranschaulichung der Kontrastempfindlichkeitsfunktion im UHD-Format (Bildseitenverhältnis 16:9). Ortsfrequenzen von 2 (links) bis 1024 (rechts) Linienpaare pro Bildbreite, Kontrast von 100 Prozent (unten) bis 0 Prozent (oben).
Aus photographischer Sicht ist es unwichtig, ob bei großen Ortsfrequenzen (Maßeinheit Linienpaare pro Längeneinheit) noch ein wenig Kontrast übertragen wird. Das interessiert nur "Pixelpeeper" und hat keinen praktischen Nutzen. In einem perfekten Bild müssen bei den erkennbaren Ortsfrequenzen 100 Prozent Kontrastübertragung vorhanden sein - nicht weniger, aber bitte auch nicht mehr, weil der Kontrast digital angehoben wurde, damit das Bild schärfer und ansprechender aussieht. Die physiologisch erkennbaren Ortsfrequenzen liegen zwischen 0 und ungefähr 1000 Linienpaaren pro Bildhöhe (in einem Kleinbild mit 24 Millimetern Höhe wären das maximal 42 Linienpaare pro Millimeter beziehungsweise 6 Millionen Bildpunkte), wobei das menschliche Auge bei den angegebenen Werten nur noch 10 Prozent des tatsächlich vorhandenen Kontrastes erkennen kann. Die größte Kontrastempfindlichkeit liegt bei einer Ortsfrequenz von zirka 200 Linienpaaren pro Bildhöhe. Der Bildeindruck wird von den sichtbaren Kontrasten im Ortsfrequenzbereich zwischen 50 und 500 Linienpaaren pro Bildhöhe dominiert, wo der wahrnehmbare Kontrast oberhalb von 50 Prozent liegt.
Wie auch immer, der Bildsensor einer Kleinbildkamera mit einem Pixelpitch von 5,3 Mikrometern kann gut 2200 Linienpaare pro Bildhöhe beziehungsweise 94 Linienpaare pro Millimeter auflösen, und das noch nicht einmal mit der vollen Farbinformation, weil in jedem Bildpunkt nur eine einzige Primärfarbe gemessen wird. Bei dieser Ortsfrequenz ist die Wahrnehmung des menschlichen Auges praktisch null, und zudem liefern die meisten (auch teuren) Objektive hier eine sehr dürftige Kontrastübertragung. Siehe zum Beispiel [3] - beim Sony FE Sonnar 35mm f/2,8 (Listenpreis 949 Euro) ist die Kontrastübertragung (MTF) hier zum Beispiel bei lediglich 50 Linienpaaren pro Millimeter mit 55 Prozent auf der optischen Achse und mit 20 Prozent in den Bildecken angegeben. Bei solchen "dürftigen" Kontrastübertragungen sollte man sich gar nicht erst Gedanken über die Bildqualität bei 100 Linienpaaren pro Millimeter mehr machen, und das schon gar nicht, wenn es sich bei den bewerteten Zahlen aus der digitalen Bildanalyse mehr um Artefakte der bildtechnischen Manipulation beim Demosaicing und der digitalen Kontrastüberhöhung handelt, als um irgendeine reale optische Information. Ferner gibt es bei Bildsensoren mit solch großer Pixelzahl Abertausende von fehlerhaften Pixeln (Hotpixel), die gar nichts oder zumindest fast nichts zur Kontrastübertragung beitragen können.
Fazit: mögen die Bildsensor-Tester dieser Welt endlich aufhören, die Pixel auf den Bildsensoren zu zählen und daraus völlig praxisferne Testurteile zu generieren. Eine sehr gute und praxistaugliche Kamera erzeugt Bilder mit 8 Megapixeln (siehe auch 4K (Bildauflösung)), wobei zwei beliebige benachbarte Bildpunkte bei allen drei Primärfarben und auch in den Bildecken einen reellen Kontrast zeigen (mit anderen Worten: die Kontrastübertragungsfunktion beträgt 100 Prozent). Die dafür erforderlichen Objektive sind erheblich teurer als die Bildsensoren, die das leisten können. Wenn alle Objektive eine solche Kontrastübertragung liefern würden wie dieses hier [4] (Listenpreis 3000 Euro), wäre es für Photographen wie in einem schönen Traum... --Bautsch23:43, 23. Dez. 2019 (CET)
Für kleinere Bildausschnitte, sollten genau aus den oben erwähnten Erwägungen übrigens besser Objektive mit kleinerem Bildwinkel (respektive längerer Brennweite) verwendet werden, anstatt im aufgenommenen Bild einen digitalen Zoom durchzuführen. Die niedrigen (schlechten) Kontrastübertragungswerte des Bildes verschieben sich hierbei nämlich von den höheren Ortsfrequenzen nach links hin zu den kleineren und somit besser wahrnehmbaren Ortsfrequenzen. --Bautsch00:06, 24. Dez. 2019 (CET)
Bautsch, danke für Deine schnelle und ausführliche Antwort. Du gehst in Deiner Erklärung beispielhaft von einer Pixelgröße von 5,3 µm bei 94 lp/mm aus. Wenn ich die Formel von oben nehme, dann komme ich bei dieser Pixelgröße auf 47 lp/mm (500 / (5,3 lp/mm * 2) = 500 / 10,6 = 47,16 lp/mm)[1] und nicht auf 94 pl/mm. Das bedeutet also, dass diese Berechnungsformel Deiner Meinung nach falsch ist? -- ηeonZERO00:15, 24. Dez. 2019 (CET)
↑Formel für Farbsensoren: Linienpaare = 500 / (Pixelgröße in µm * 2); Formel für Monochromsensoren: Linienpaare = 500 / (Pixelgröße in µm * 1,41) gemäß OptoWiki
Nachtrag: Ah, ich sehe gerade meinen Fehler in der Antwort. Du redest vom Pixelabstand, nicht von der Pixelgröße. Wie groß ist denn der Sensorpixel aus Deinem Beispiel? Das ist wichtig für die Antwort auf meine Frage von oben.
Der Abstand der Pixelmittelpunkte und die Pixelgröße sind identisch, wenn zwischen der Pixeln kein elektrisch isolierender Steg wäre. Da ist natürlich einer, dieser Umstand wird allerdings durch die Verwendung von Mikrolinsenfeldern kompensiert, die auch das Licht über den (lichtunempfindlichen) Stegen zur lichtempfindlichen Pixelmitte lenken. Das kann sowohl für die Lichtausbeute als auch für die Ortsauflösung ignoriert werden.
Der Faktor zwei zwischen den beiden Formeln beruht sicherlich auf der in der Optik-Branche verbreiteten Faustformel, dass Bayer-Sensoren nur ungefähr eine halb so große Farbauflösung liefern wie sie Pixel haben, da jedes einzelne Pixel nur eine der drei Primärfarben rot, grün und blau erfasst. Siemens-Sterne sind in der Regel jedoch ohne Farben, so dass die Firmware der Kameras beim sogenannten Demosaicing alle Farben wegrechnet und dafür möglichst viel schwarz-weiß Kontraste hinrechnet. Dadurch können sogar bei Ortsfrequenzen jenseits der Nyquist-Grenze rein rechnerisch noch Kontraste auftreten, die im Objekt (Siemens-Stern) zwar durchaus vorhanden sein können, vom Objektiv aber gar nicht übertragen wurden - neudeutsch würde man das wohl als "Fake" bezeichnen. Diese Verfahren dienen dazu, Bilder mit geringer Auflösung ansehnlicher zu machen (Smartphone-Kameras machen das heutzutage "vorbildlich") oder numerische Ergebnisse von Testtafelaufnahmen mit hoher Bildauflösung bis zur Auflösungsgrenze der Bildsensoren hochzutreiben, ohne dass dies objektiv (oder auch wörtlich "durch das Objektiv") irgendeine Verbesserung der optischen Abbildung mit sich bringt. Deswegen kritisierte ich dieses früher durchaus angebrachte, heute aber obsolete Messverfahren dahingehend, dass man einfach auch gleich die Pixel auf dem Bildsensor zählen kann, ohne eine Messung durchzuführen !
Du schreibst, Zitat: "Fazit: mögen die Bildsensor-Tester dieser Welt endlich aufhören, die Pixel auf den Bildsensoren zu zählen" Aber genau das tun sie nicht. Ohne die Sensorauflösung zuvor zu ermitteln untersuchen sie schlicht das Foto und berechnen dann daraus die effektive Auflösung im Zusammenspiel von Optik und Sensorik (zum Beispiel per Siemensstern). Meine Frage von oben zielt darauf ab, dass sie im Ergebnis mitunter eine weitaus höhrere optische Auflösung errechnen, als die Sensorauflösung zu erfassen vermag. Ich will herausfinden, ob die Formel für die vom Sensor maximal erfassbare optische Auflösung gemessen an der Pixelgröße wirklich korrekt ist oder ob die Testergebnisse/die Messmethoden fehlerhaft sind oder ich einfach nur etwas nicht richtig verstanden habe. Deine Antwort ist interessant, hilft mir diesbezüglich aber leider nicht weiter. Gruß, -- ηeonZERO00:19, 24. Dez. 2019 (CET)
Die oben von mir beschriebenen Verfahren zur Bildaufbereitung durch die Kameras und zur "Messung" von Siemens-Sternen dienen bei Smartphone-Kameras mit 12 Megapixel oder bei Systemkameras mit 20, 40 oder gar 60 Megapixelkameras vor allem dazu, möglichst "gute" Ergebnisse zu liefern. Die Dead-Leaves-Methoden (siehe auch ISO 12233 ([5]) oder [6]) liefern da erheblich praxisnähere Ergebnisse, da die Testtafeln mehrfarbig sein können, und keine regelmäßigen Muster haben, die von der automatischen Bildaufbereitung ohne weiteres systematisch verbessert werden können. Hierbei ergeben sich dann auch keine fiktiven Kontraste bei unsinnig hohen Ortsfrequenzen... --Bautsch13:19, 24. Dez. 2019 (CET)
Das ist sehr informativ und ich würde gerne auf so vieles davon näher eingehen. Wenn Du, Bautsch, die Geduld davür aufbringen kannst, würde ich das gerne nach Klärung der obigen Frage nachholen. Das hier entwickelt sich für mich zu einem wirklich interessanten Gespräch...
Doch zunächst einmal: Du schreibst, Zitat: "Der Abstand der Pixelmittelpunkte und die Pixelgröße sind identisch... [der elektrisch isolierender Steg dazwischen wird] durch die Verwendung von Mikrolinsenfeldern kompensiert." Du gehst in Deinem Beispiel also von den foglenden Daten aus: KB-Sensor mit 67 MP, woraus 5,3 µm Pixelgröße und 94 lp/mm resultieren (mehr kann der Sensor also selbst unter idialsten Bedingungen nicht erfassen).
Meine eingangs genannten Quellen kommen bei den Abmessungens eines KB-Sensors zum folgenden Ergebnis: Aus 67 MP resuliteren eine Auflösung von 10025x6683 Pixeln[1] (3:2) und eine Pixelgröße von 3,59 µm[2] (in Höhe und Breite). Die Formel für Lienenpaare kommt mit diesen Daten auf 70 lp/mm bei Farbsensoren (500 / (3,59µm * 2) = 500 / 7,18 = 69,63 lp/mm) bzw. bei Monochromsensoren auf 99 lp/mm (500 / (3,59µm * 1,41) = 500 / 5,06 = 98,81 lp/mm).[3]
↑Übereinstimmend mit Sensorberechnungen auf vision-doctor.com zur Berechnung der Pixelgröße in µm (mit Nachkommastellen) sowie Pixelgrößen Rechner auf lcdtech.info als zweite Referenz (ohne Nachkommastelle, dafür mit MP-Berechnung) - bei einer 1.7047 Zoll Sensorsdiagonale (das entspricht 43,3mm eines typischen KB-Sensors mit einer Seitenlänge von 24 x 36 mm)
↑Formel für Farbsensoren: Linienpaare = 500 / (Pixelgröße in µm * 2); Formel für Monochromsensoren: Linienpaare = 500 / (Pixelgröße in µm * 1,41) gemäß OptoWiki
Wie kommt es zur Diskrepanz der jeweils berechneten Pixelgröße (5,3 µm vs 3,59 µm)? Ein Zahlendreher (5,3 statt 3,5)?
Sorry, da habe ich mich ganz offensichtlich vertippt und / oder verrechnet, denn bei 6683 Zeilen auf der Kleinbildhöhe von 24 Millimetern ergeben sich 24 Millimeter / 6683 = 3,6 Mikrometer. --Bautsch16:09, 26. Dez. 2019 (CET)
Deine 97 lp/mm liegen nahe an den von mir berechneten 99 lp/mm, weshalb ich davon ausgehe, dass Du mit den Werten für Monochromsensoren gerechnet hast. Üblicherweise sind Farbsensoren in den Kameras verbaut (mal von einigen Leica Kameras abgesehen). Die Bayer-Farbsensoren erfassen, wie Du bereits geschrieben hast, rot, grün und blau mit je einem separaten Pixel, die dann zu einem Farbwert zusammengerechnet werden. Daher die Abweichung der Auflösung zwischen Farb- und Monochromsensoren. Allerdings wäre es theoretisch denkbar, jeden Pixel, der ursprünglich für nur eine Farbe zuständig ist, zur Erfassung eines eigenständigen Pixels heranzuziehen, wenn der Farbsensor nur noch Monochrom abbilden soll. Dadurch würde sich die Auflösung eines Farbsensors auf die Auflösung eines Monochromsensors erhöhen. Genügend Rechenkraft in der Kamera vorausgesetzt, ließen sich auf diese Weise sogar Farbaufnahmen hin zur höheren Monochromauflösung berechnen, indem man beide Aufnahmemethoden "übereinander legt" und zu seinem Bild zusammenfügt. Das ist aber nur meine ganz persönliche Theorie. Huawei macht soetwas in der Art in ihrem P20 Pro - jedoch greifen sie dabei auf einen zusätzlichen monochromen Sensor zurück, nehmen also nicht einen einzelnen Farbsensor dafür. Deiner Benutzerseite entnehme ich, dass Du am Optischen Institut der Technischen Universität Berlin promoviert hast und jetzt hauptberuflich als wissenschaftlicher Mitarbeiter bei der Stiftung Warentest beschäftigt bist. Daher meine Frage gerichtet an Deine praktische Erfahrung, ob ich mit meiner Theorie richtig liege, in der Hoffnung, dass wir uns damit nicht auf den Weg der Theoriefindug begeben... Das wäre dann nämlich eine plausible Erklärung auf meine eingangs gerichtete Frage. Gruß, -- ηeonZERO10:07, 25. Dez. 2019 (CET)
Keine Sorge, es handelt sich nicht um Theoriefindung, sondern um seit über einhundert Jahren bekannte und veröffentlichte Fakten.
Ein Bayer-Sensor kann bunte Objekte übrigens nicht monochrom abbilden, da in jedem Bildpunkt nur eine Primärfarbe gemessen wird, die für die tatsächliche Objektfarbe und -helligkeit nicht notwendiger Weise repräsentativ ist. Unter der (bei Siemens-Sternen meist zutreffenden) Annahme, dass das Objekt monochrom ist, kann die Farbinformation verworfen und nur die Helligkeit ausgewertet werden. Gut für die Bewertung von sehr geringen Kontrasten an kleinen Strukturen, aber für die Bildqualität bei realen Objekten liefert das wegen der fehlenden Farbauflösung in der Regel keinen Mehrwert, und schon gar nicht, um Bildausschnitte zu vergrößern oder Großplakate herzustellen, die auch aus der Nähe betrachtet als ansehnlich empfunden werden. --Bautsch16:09, 26. Dez. 2019 (CET)
Du schreibst "kann die Farbinformation verworfen und nur die Helligkeit ausgewertet werden". Nehmen wir ein Bild, dass per Farbsensor aufgenommen wurde und daher unter idealsten Bedingungen auf diesem Sensor optisch 70 lp/mm erfaßt hat (mehr geht nicht). Bedeutet das jetzt, dass ich in meinem Computerprogramm lediglich die Farbsättigung auf 0 setzten muss (=s/w-Foto) und schon sind es 99 lp/mm? Das verstehe ich nicht; das sollte nach meinem bisherigen Verständnis so nicht funktionieren. *grübel* Gruß. -- ηeonZERO18:43, 26. Dez. 2019 (CET)
Bei einer farblosen Vorlage spricht jedes Farbpixel eines Bayer-Sensors an, wenn das Objekt Licht emittiert. Wenn kein Licht emittiert wird, dann registriert das entsprechende Pixel den Wert für Schwarz. Wenn eine homogene rote, grüne oder blaue Fläche aufgenommen wird, dann sprechen jedoch nur die jeweiligen Pixel des Bayer-Sensors an, die beiden anderen Primärfarben registrieren dann aber kein Lichtsignal. Wenn die Farbsättigung im Bildbearbeitungsprogramm nach der Aufnahme auf Null gesetzt wird, ergibt sich ein grau-schwarzes Muster, aber keine homogene Fläche, in der alle Bildpunkte die gleiche Helligkeit haben, so wie in der Vorlage. Ein realistisches, homogenes Bild erhält man hier nur mit einem monochromen Bildsensor (also mit einem ohne Farbmosaik). --Bautsch23:32, 26. Dez. 2019 (CET)
Nach der oben genannten Faustformel kann man mit einem Bayer-Sensor nur die halbe Farbauflösung erreichen, so dass die theoretisch erreichbare in beiden Richtungen (horizontal und vertikal) um den Faktor Wurzel-2 verringert wird, insgesamt als um den Faktor 2. 99 / 70 entspricht diesem Faktor Wurzel-2. Aber ich möchte noch einmal ausdrücklich darauf hinweisen, dass optische Tiefpässe, die Beugungsbegrenzung durch das Objektiv und Abbildungsfehler die praktisch erreichbare Auflösung in der Regel bei deutlich niedrigeren Ortsfrequenzen limitieren. Bei Bayer-Sensoren mit unsinnig vielen Pixeln, wird der optische Tiefpass meistens weggelassen, weil die Beugungsbegrenzung so stark ist, dass ein denkbar kleiner Objektpunkt (wie zum Beispiel ein Fixstern) auf dem Bildsensor sowieso immer mehrere Pixel beleuchtet. Weitere Information in meinem Wikibook: Ortsfrequenz, Beugungsbegrenzung, Bildsensoren. --Bautsch09:43, 28. Dez. 2019 (CET)
Du schreibst "[...] so dass die theoretisch [xxx] erreichbare in beiden Richtungen [...]"; an der Stelle von xxx hast Du ein Wort verschluckt, sodass ich den Satz nicht verstehe. Meist Du "Auflösung"? Wenn ja, dann bestätigst Du mit diesem Satz - wenn ich das richtig verstehe - lediglich, dass die Rechnung mit den 70 zu 99 lp/mm stimmt, bezogen auf Farb- und Monochrom-_Sensoren_. Meine Frage lautete jedoch, ob ein _auf einem Farbsensor erfaßtes Bild_ an optischer Auflösung gewinnt (von 70 hin zu 99 lp/mm), wenn man die Farbhinformation daraus herausrechnet, es also zu einem Monochrom-Bild umwandelt.
Ich bin heute leider den ganzen Tag unterwegs, weshalb ich Deine oben verlinkten Artikel erst morgen lesen werde. Ich freue mich schon darauf... Gruß, -- ηeonZERO06:52, 29. Dez. 2019 (CET)
Die "theoretisch erreichbare" bezieht sich unmittelbar auf "Farbauflösung" meines ersten Satzes. Bei einem Bayer-Sensor kann die Farbinformation nicht herausgerechnet werden, da die Farbinformation inhärent erfasst wird. Durch das Demosaicing (Anti-Aliasing) werden zwar störende farbige Artefakte entfernt, dabei geht ohne Kenntnis und Annahmen zum photographierten Objekt jedoch Bildinformation verloren. Da Siemens-Sterne keine Farbinformation enthalten, kann beim Demosaicing keine Farbinformation verloren gehen, und durch die Annahme und die (rechnerische) Fortsetzung von schwarz-weißen Kanten zur Mitte des Siemens-Sterns hin wird eine optische Auflösung suggeriert, die bei der optischen Abbildung gar nicht erreicht wurde und die daher bei realen farbigen Objekten (also keinen Siemens-Sternen) in der Abbildung auch gar nicht erreicht wird. Das Einzige, was damit erreicht wird, sind scheinbar hohe Ortsfrequenzen bei der Kontrastübertragung mit sehr geringen Bildkontrasten (zum Beispiel nur 10 Prozent Bildkontrast an perfekten schwarz-weißen Objektkanten). Diese zu Bewerten und zu Beurteilen, um etwas über die Bildqualität einer Digitalkamera auszusagen, ist nicht zielführend, weil sie erstens nicht real sind und zweitens der geringe bewertete Kontrast gar nicht für hochwertige Bilder ausreichend ist. --Bautsch09:41, 29. Dez. 2019 (CET)
Ah, so verstehe ich das. Danke für Deine Erklärung. Das bedeutet also, dass ein monochormes Objekt, dass mit einem Farbsensor aufgenommen wurde, ebenfalls die 99 lp/mm erreichen kann (max. - bei dem Sensor aus Deinem Beispiel). Richtig? Das erklärt vieles. Danke. :o)
Ich war viel länger unterwegs, als ursprünglich gedacht, muss auch gleich wieder weg und werde erst am 3.1. wieder verfügbar sein. Deine oben verlinkten Artikel konnte ich leider(!) noch ncht lesen. Werde ich aber nachholen und mich dann melden. Ich wünsche Dir einen guten Rutsch ins neue Jahr. Vielen herzlichen Dank für Deine Geduld mit mir und meinen Fragen. Gruß, -- ηeonZERO17:30, 31. Dez. 2019 (CET)
Wow! Das Buch, dass Du, Bautsch, geschrieben hast, ist wirklich toll. Digitale bildgebende Verfahren mag von Dir als Lehrbuch gedacht sein, aber aus meiner Sicht ist es nicht nur für Studenten geeignet, sondern auch für interessierte Laien wie mich. Und es ist frei verfügbar bei wikibooks.org. Ich bin beeindruckt. Hut ab.
Ich weiß dass es unhöflich ist so lange nicht zu antworten und dafür entschuldige ich mich. Ich war viel später zurück als ursprünglich geplant. Bei mir ist derzeit viel los. So konnte ich Montag die Kapitel "Grundlagen", "Bildaufnahme" und einen Teil von "Lichtwandlung" lesen; heute (Donnerstag) kam ich erst zu den Rest des Lichtwandlungs-Kapitels. Da das ein Wiki ist, habe ich dort einige kleinere Korrekturen vorgenommen. Mache einfach Rückgängig, was Dir nicht gefällt.
Um zum Thema zurückzukehren: Es wäre nett, wenn Du mir sagen könntest, ob ich Dich oben wirklich richtig verstanden habe, da sich daraus dann Folgefragen ergeben: Ein monochormes Objekt (wie der Siemensstern), dass mit einem Farbsensor erfasst wurde, kann also ebenfalls die 99 lp/mm erreichen (max. - bei dem Sensor aus Deinem Beispiel)? Gruß, -- ηeonZERO12:09, 9. Jan. 2020 (CET)
Ich freue mich, wenn ich auf diesem Weg erfahre, dass das Wikibook gelesen wird und einen Nutzen hat. Ich freue mich auch, wenn dort Korrekturen vorgenommen werden und habe keinerlei Unhöflichkeit empfunden, auch nicht wegen vermeintlich später Antworten.
Wenn wir uns auf die folgende Formulierung einigen können, bin ich dabei: "Bei einem schwarz-weißen Objekt, dass mit hinreichender optischer Auflösung des verwendeten Objektivs und einem Bayer-Sensor erfasst wurde, kann unter Berücksichtigung des Wissens, dass das Objekt unbunt ist, die volle Bildauflösung des Bildsensors ausgeschöpft werden." --Bautsch14:27, 9. Jan. 2020 (CET)
Danke für Dein Verständnis bezüglich der späten Antworten; das wird in der nächsten Zeit leider auch nicht besser werden.
Dank Deiner Antwort kann ich jetzt mit konkret berechneten Daten arbeiten, die zu meiner weiter unten stehenden Folgefrage führen: Dein Beispiel bezog sich auf 67 Megapixel, aber ich möchte auf einen 61 Megapixel-Kleinbildsensor eingehen, da er zu einem ganz konkreten Fall passt. Er hat eine Pixelgröße von 3,75 µm in Höhe und Breite. Das entspricht genau der Größe der Lichtpunkte (genauer des Beugungsscheibchens) des (in diesem Beispiel absolut fehlerfreien) Objektivs bei Blende F2.8. Unter den von Dir genannten Bedingungen könnten damit 95 lp/mm erfaßt werden. Das entspricht der maximal möglichen Auflösung sowohl des F2.8'er Objektivs als auch des Sensors. Ich setze darüber hinaus die folgenden Gegebenheiten voraus (bitte korrigiere mich hier, falls ich damit falsch liege):
a) Unter den von Dir genannten Bedingungen erfaßt jeder Sensorpixel je einen Lichtpunkt. Daraus folgt:
b) Die Auflösung von 95 lp/mm läßt sich durch die Firmware rechnerisch nicht weiter erhöhen, jedenfalls nicht ohne damit die Megapixelauflösung der Bilddatei zu erhöhen.
c) Was passiert bei Verwendung eines fehlerfreien Objektivs mit kleinerem Blendenwert und somit höherer optischer Auflösung?: Mit einem 61-MP-KB-Sensor können noch immer nicht mehr als 95 lp/mm erfaßt werden.
d) Was passiert bei Verwendung eines fehlerfreien Objektivs mit größeren Blendenwert und somit niedrigerer optischer Auflösung?: Die erfaßte optische Auflösung sinkt, könnte im Ergebnis unter Idealbedingungen aber wieder auf max. 95 lp/mm hochgerechnet werden (die oben angesprochenen Firmwaretricks).
Das bereits erwähnte Testlabor ermittelt aus einem Foto, das mit einem 61 MP-Kleinbildsensor aufgenommen wurde, jedoch eine Auflösung von 101 lp/mm. Bei einem Foto eines 50(!) MP großen KB-Sensor (8660x5774 Pixel = 4,16 µm = max. 85 lp/mm wären hier möglich) kommen sie sogar auf 102 lp/mm. Wie ist so etwas möglich? -- ηeonZERO23:20, 10. Jan. 2020 (CET)
Nachtrag: Anders formuliert haben wir oben festgestellt, dass die Formlen für die Berechnung der lp/mm sowohl bei Deiner als auch bei meiner Berechnung im Ergebnis übereinstimmen, obwohl wir unterschiedliche Rechenwege benutzt haben. Das deutet darauf hin, dass der Fehler nicht in den Formeln zu finden ist. Aber wenn ich ganz simpel 5774 / 24mm (der Höhe des 50-MP-KB-Sensors sowohl in Pixel als auch in mm)=240 Linien/mm : 2 rechne, komme ich nicht auf max. 85 lp/mm sondern auf 120 lp/mm, wenn wirklich jeder Pixel mit je einem Lichtpunkt versorgt wird.
Zum Vergleich hier noch einmal der andere Weg in kompletter Form, der im Ergebnis auf max. 85 lp/mm des 50 MP-Sensors kommt: Die Auflösung bei 50 MP bei einem Seitenverhältnis von 3:2 ergibt 8660x5774 Pixel.1 Bei einer Sensorgröße in Pixeln X-Richtung von 8660 und den Sensormaßen von 36mm x 24mm des KB-Sensors ergibt sich eine Pixelgröße von 4,16 µm im Quadrat.2 (untere Eingabemaske) Daraus ergeben sich 500 / (4,16 µm * 1.41) = 85 lp/mm.3 (hier wie besprochen die Berechnung für Monochromsensoren)
Die 3,8 µm kommen bei meiner Rechnung mit 61 Megapixel und Vollformatsensor auch heraus, allerdings resultieren daraus 132 Linienpaare pro Millimeter (beziehungsweise 3158 Linienpaare pro Bildhöhe):
Bezahlbare Objektive (damit meine ich maximal vierstellige Eurobeträge) werden solche Auflösungen auch auf der optischen Achse (für sogenannte paraxiale Strahlen) nicht leisten, jedenfalls nicht mit nennenswerten Kontrasten.
Wird die Blendenzahl kleiner, verstärkt sich unweigerlich der Öffnungsfehler des Objektivs und somit sinkt die optische Auflösung. Wird die Blendenzahl größer, verstärkt sich unweigerlich die Beugungsbegrenzung der optischen Abbildung und somit sinkt die optische Auflösung. Für weitere Recherchen siehe auch kritische Blende.
Ein brauchbares Objektiv liefert bei 1000 Linienpaaren pro Bildhöhe (bei einem Vollformatsensor mit 24 Millimetern Bildhöhe also bei 41,7 Linienpaaren pro Millimeter oder bei einer Smartphone-Kamera mit 4,2 Millimetern Bildhöhe also bei 238 Linienpaaren pro Millimeter) 100 Prozent Kontrast. Wenn ein hochwertiges Objektiv bei 2000 Linienpaaren pro Bildhöhe (beim Vollformatsensor also bei 83,3 Linienpaaren pro Millimeter oder bei der Smartphone-Kamera bei 476 Linienpaaren pro Millimeter) dann eventuell noch 50 Prozent Kontrast liefern kann, sind die entsprechenden Strukturen schon recht flau, und das sollte daher nicht überbewertet werden. Bei 3000 Linienpaaren pro Bildhöhe (beim Vollformatsensor also bei 250 Linienpaaren pro Millimeter) ist der Kontrast der optischen Abbildung praktisch null und ein solches Auflösungsvermögen eines Bildsensors sollte aus meiner Sicht daher besser gar nicht bewertet werden. --Bautsch12:37, 13. Jan. 2020 (CET)
Hast Du Dich da verrechnet? Die von Dir verwendete Formel ist auch im optowiki zu finden, jedoch werden laut der Quelle damit die Linien und nicht die Linienpaare pro Millimeter berechnet. Für Linienpaare werden gemäß dieser Quelle die 1000 durch 2 geteilt; also kann man auch gleich 500 schreiben. Das wäre dann:
Farbe, beziehungsweise s/w (wie beim Siemensstern)
In Deiner Rechnung verwendest Du den Faktor 2 für Farbsensoren; ich will hier jedoch auf das maximal Mögliche hinaus, also auf den Wert, der in keiner Messung hätte überschritten werden können. Und nach dem was Du geschrieben hast, kämen wir auf die Werte des Monochromsensors (Faktor 1,41), natürlich nur unter den von Dir weiter oben genannten Bedingungen, von denen wir in diesem Beispiel ausgehen. Gruß, -- ηeonZERO17:06, 13. Jan. 2020 (CET)
Ich hatte den Divisor zwei für die Paarbildung bei den Linien eingesetzt und nicht für den Bayer-Sensor, um die maximale Ortsfrequenz auszurechnen, bei der unter optimalen Umständen (also schwarzweiße Vorlage und korrigiertes Objektiv) noch Kontrast gemessen werden kann. Bei farbigen Motiven ist die Auflösung entsprechend der Faustfomel um den Faktor zwei kleiner, liegt also bei rund 66 Linienpaare pro Millimeter. --Bautsch17:20, 13. Jan. 2020 (CET)
Was bedeutet das jetzt? Ist die Formel aus dem optowiki falsch bezogen auf deren Angaben zu Monochromsensoren? Denn Monochromsensoren erfassen je Sensorpixel einen Lichtpunkt, ohne Auflösungsverluste durch Demosaicing oder andere Verfahren. Zumindest wenn ich die Beschreibung in Deinem Buch richtig verstanden habe. Es sollte dann keinen Unterschied geben zwischen der maximalen Ortsfrequenz und der maximalen Auflösung, die der Sensor zu erfassen vermag. Das ist die Grundlage meiner Überlegung die dazu führt, dass ich unter den von Dir weiter oben genannten Bedingungen den Farbsensor in der Berechung gleich setze mit dem Monochromsensor. -- ηeonZERO17:41, 13. Jan. 2020 (CET)
Querrechnung: Ein 61 Megapixel-Sensor mit 6320 Pixel in der Höhe und einer Abmessung im Kleinbildformat von 24mm in der Höhe enthält 6320 / 24 = 263,3 Linien pro Millimeter, was geteilt durch 2 = 131,6 Linienpaare pro Millimeter ergibt. Das entspricht Deiner Berechung der Ortsfrequenz von oben. Das war klar, denn Deine Formel ist leicht nachvollziehbar und absolut schlüssig. Ganz entgegen der Formel aus dem Optowiki, aus der ich mir weder den Faktor 2 für Farbsensoren herleiten konnte (das kann ich jetzt dank Deiner Erklärung) noch den Faktor 1,41 bei Monochromsensoren. D.h. herleiten läßt sich der Faktor 1,41 durch deren Beschreibung zwar, aber ich verstehe das nicht, Zitat "Für monochrome Anwendungen multipliziert man die Pixelgrösse mit 1.41 (=Wurzel aus 2) und erhält so die Diagonale des Pixels". Ich bin einfach gestrickt und meine ganz simple logische Betrachtung sagt mir, dass ich für die Berechnung der Linien die Höhe des quadratischen Sensorpixels, aber nicht seine Diagonale benötige. *grübel*
Wir sind dem Ziel, meine eingangs gestellte Frage zu beantworten, jetzt sehr nahe. Dank Deiner obigen Beschreibung weiß ich nun, unter welchen Bedingungen ein Bayer-Farbsensor die Auflösung eines Monochromsensors (oder sogar noch mehr?) erreicht. Wenn wir noch klären können, wie die Diskrepanz zwischen der Ortsfrequenz und der laut Optowiki tatsächlichen Auflösung eines Monochromsensors entsteht und warum der Bayer-Farbsensor davon nicht betroffen ist, dann haben wir das Ziel erreicht. Gruß, -- ηeonZERO09:34, 14. Jan. 2020 (CET)
Zu dem Faktor Wurzel(2) = 1,41... kann ich nichts sagen, außer dass bei einem Quadrat die Diagonale nach dem Satz des Pythagoras um diesen Faktor länger ist als die Seitenkanten. Ich könnte mir nur vorstellen, dass dieser Faktor eingesetzt wird, um die maximale Ortsfrequenz auf der 45°-Diagonalen zu bestimmen, wüsste jedoch nicht, wie uns das hier weiterbringen sollte. Ich vermute, dass dieser Faktor 1,41... als "Kompromiss" oder empirischer Erfahrungswert zwischen dem allgemeinen Faktor 2 der von mir (und optowiki) genannten Faustformel und dem Faktor 1 bei schwarz-weißen Vorlagen liegt, wo auch mit Bayer-Sensoren die volle, bei monochromen Bildsensoren mögliche optische Auflösung erreicht werden kann. Das hätte dann allerdings nichts mit der Pixeldiagonale zu tun. --Bautsch13:36, 14. Jan. 2020 (CET)
Im Optowiki steht explizit etwas von "Pixeldiagonale", also wird auch das gemeint sein. Es ist gut möglich, das denen ein Fehler unterlaufen ist und sie aus versehen die Berechnungsformel für die 45°-Diagonale in ihre Wissensdatenbank überführt haben. Den von Dir als Alternative angesprochenen empirischen Erfahrungswert, der das wahre Auflösungsvermögen entsprechender Sensoren aufzeigt, kann es doch nur für Farbsensoren geben; bei Monochromsensoren gibt es schließlich keinen technischen Grund für eine Auflösungsminderung (oder?).
Zitat "Faktor 1 [...] die volle, bei monochromen Bildsensoren mögliche optische Auflösung". Ich frage nur noch einmal nach, um wirklich jedes Missverständnis zu vermeiden: Faktor 1 bedeutet doch, dass die Auflösung eines monochromen Sensors identisch ist mit der maximalen Ortsfrequenz. Daraus ergibt sich, dass die Formeln zur Berechnung der Sensorauflösung wie folgt lauten:
Für Monochromsensoren:
Für Bayer-Farbsensoren:
Das entspricht (Kurzschreibweise im Stil vom Optowiki):
Für Monochromsensoren: Linienpaare_pro_mm = 500 / Pixelgrösse
Für Bayer-Farbsensoren: Linienpaare_pro_mm = 500 / (Pixelgrösse * 2) (sobald nicht die Bedingungen von oben zutreffen - dann wäre auch bei einem Farbsensor die Formel für Monochromsensoren zutreffend)
Keine Ahnung, was in dem OptoWiki mit "monochrome Anwendung" gemeint ist. Ich hatte es so verstanden, dass damit gemeint ist, dass schwarz-weiße Vorlagen mit einem Bayer-Sensor aufgenommen werden. Wie auch immer, die beiden Formeln sind aus meiner Sicht korrekt, und die maximal erreichbare Auflösung von monochromen und insbesondere schwarzweißen Vorlagen mit einem Bayer-Sensor liegt irgendwo zwischen diesen beiden Ortsfrequenzen. --Bautsch13:14, 15. Jan. 2020 (CET)
Ich hatte das bislang so verstanden, dass das OptoWiki damit zwischen Monochrom- und Farbsensoren unterscheidet. Auf Deine Idee mit der schwarz-weißen Vorlage bin ich leider nicht selbst gekommen, aber sie klingt interessant, auch wenn sie damit kolossal daneben liegen würden. Wie oben bereits geschrieben kommt das Testlabor bei der Analyse eines Fotos, das mit einem 50 MP großen KB-Sensor aufgenommen wurde, auf 102 lp/mm. Die maximale Ortsfrequenz liegt bei 120 lp/mm, was gut dazu passt. Das Testergebnis muss ja kleiner bis gleich hoch sein. Nach der Formel des OptoWikis käme man für "monochrome Anwendungen" mit ihrem Faktor 1,41 auf max. 85 lp/mm, die ein 50 MP KB Sensor erfassen kann. Diese Formal kann also nicht stimmen, egal ob sie für Monochromsensoren oder für "Byer-Farbsensoren in monochromer Anwendung" gedacht war. Es spielt auch keine Rolle ob sie mit "monochromer Anwendung" womöglich etwas vollkommen anderes meinen, denn diese Formel bleibt damit noch immer nicht für die hier behandelten Fälle anwendbar. Gruß, -- ηeonZERO21:37, 15. Jan. 2020 (CET)
Blende und optische Auflösung vs Kontrast und effektive Bildauflösung in lp/mm
Es gibt ein weiteres Phänomen, das ich mir einfach nicht erklären kann: Ein Testlabor ermittelte an der 61 Megapixel auflösenden Sony Alpha 7R IV mit dem Objektiv Sony FE 24-105 mm F4 G OSS bei Blende F8 eine Auflösung von 90 lp/mm.1 Das Beugungsscheibchen hat bei F8 jedoch einen Durchmesser von 10,73 µm (=(2,44*550nm*F8) / 1000), woraus sich eine maximale optische Auflösung von 47 lp/mm ergibt (=500 / 10,73µm). Wie konnten sie unter diesen Bedingungen 90 lp/mm messen? -- ηeonZERO21:37, 15. Jan. 2020 (CET)
Die 5,4 Mikrometer Beugungsscheibchendurchmesser sorgen dafür, dass bei maximal 93 Linienpaaren pro Millimeter (bei schwarz-weißen Vorlagen halt auch mit einem Bayer-Sensor) noch ein sehr hoher Kontrast erreicht werden kann. Das heißt aber nicht, dass bei 101,6 Linienpaaren pro Millimeter kein Kontrast mehr vorhanden ist:
Besselfunktion für Beugungsscheibchen mit
Beugungsscheibchen im Bild
Überlagerung mit Abstand 1,0 zwei Bildpunkte gut unterscheidbar, die Modulation zwischen den beiden Maxima beträgt fast 90%
Überlagerung mit Abstand 0,5 zwei Bildpunkte praktisch nicht unterscheidbar, die Modulation zwischen den beiden Maxima beträgt unter 1%
Bei Beugungsauflösung mit hohem Kontrast (fast 90 Prozent Modulation) können zwei benachbarte Beugungsscheibchen gut von einander getrennt gesehen werden (obere Bildreihe). Bei einer Halbierung des Abstands (also bei doppelter Ortsfrequenz) ist die Modulation unter 1 Prozent, also praktisch nicht mehr wahrnehmbar. Je nachdem bei welcher Restmodulation die Schwelle festgelegt wird, ergeben sich also unterschiedliche maximale Ortsfrequenzen. Ich würde sagen, dass ein Modulation von 90 Prozent eine sehr gute Bildqualität hervorruft, und alles was darunter liegt ist entsprechend schlechter.
Die Modulation in Abhängigkeit vom Schwarzwert. Der Schwarzwert ist einheitenlos in Anteilen des Weißwertes angegeben.
Eine Modulation von 50 Prozent erzeugt ein als ziemlich flau empfundenes Bild, denn Schwarz hat dann nicht mehr die Leuchtdichte 0 (das wären 100 Prozent Kontrast), sondern ein Drittel der hellsten Leuchtdichte. --Bautsch11:51, 16. Jan. 2020 (CET)
Wie kommst du darauf, dass man 1% Helligkeitsunterschied nicht mehr wahrnehmen kann? Ich habe auf meinem PC festgestellt, dass ich deutlich weniger als 1% wahrnehmen kann (z.B. Graustufe 127 und 128). Die Nichtwahrnehmbrakeit kommt eher, daher, dass man meistens weiße Linien verwendet, also nahe Graustufe 255. Wenn man zwischen 2 Linien mit Graustufe 255 eine Linie mit Graustufe 253 hat, kann man tatsächlich keinen Unterschied mehr festlegen, wenn der Monitor richtig kalibriert ist (also so dass Graustufe 255 tatsächlich weiß ist und nicht hellgrau). --MrBurns (Diskussion) 16:18, 16. Jan. 2020 (CET)
An Stufen mit plötzlicher Helligkeitsänderung (je nach tatsächlicher Leuchtdichte und Kalibrierung des Bildschirms, siehe übrigens auch Machsche Streifen) ist es möglich, solch geringe Helligkeitsunterschiede zu sehen, aber nicht zwischen den beiden Maxima und dem dazwischen liegenden Minimum bei der Überlagerung zweier Beugungsscheibchen in einem reellen Bild (siehe Beispiel oben). Solche reellen Bilder entstehen, wenn zum Beispiel ein Doppelstern mit zwei gleich hellen Sternen optisch abgebildet wird (geometrisch würden nur zwei Punkte im Bild zu sehen sein, tatsächlich sind es zwei Beugungsscheibchen). --Bautsch17:17, 16. Jan. 2020 (CET)
Ich verstehe. Das bedeutet, dass mit 5,4 µm Beugungsscheibchendurchmesser (zu erreichen bei Blende F4) dank des hohen Kontrasts gut 93 lp/mm erfaßt werden können. Bei einer Erhöhung des Blendenwerts erhöht sich die Größe und damit der Abstand der Lichtpunkte zueinander. Sie sind nun schwerer von einander unterscheidbar und die erfaßbare Auflösung sinkt. Mit der Eingangs angesprochenden Blende F8 erhält das Beugungsscheibchen einen Durchmesser von 10,8 µm, wodurch sich der Abstand halbiert den die Lichtpunkte zueinander einnehmen; die optische Auflösung sinkt auf die doppelter Ortsfrequenz (anders formuliert halbiert sich die optische Auflösug im Vergleich zu F4 von 93 lp/mm auf knapp 47 lp/mm).
Was ich nicht verstehe ist, dass sich dies nicht im Messergebnis widerspiegelt. So müßten die erfaßten und damit messbaren Details sinken, der Grauring im Siemensstern im Durchmesser deutlich zunehmen, das Messergebnis deutlich auf die Auflösungsminderung hinweisen. Schließlich soll die Messung die erfaßte Auflösung ermitteln. Wie konnte das eingangs genannte Testlabor also aus einem Foto, das bei Blende F8 aufgenommen wurde, eine Auflösung von 90 lp/mm ermitteln, wenn dem Kamerasystem optisch nur 47 lp/mm zur Verfügung standen? Gruß, -- ηeonZERO08:35, 17. Jan. 2020 (CET)
Genau genommen verändert sich der strahlengeometrische Abstand der Mittelpunkte der Beugungsscheibchen bei größeren Blendenzahlen nicht, sondern deren Durchmesser wird größer, und dadurch die Überlappung stärker und der Kontrast niedriger. Bei der Blendenzahl 8 und einem Vollformatsensor beginnt ab 1100 Linienpaaren pro Bildhöhe (oder 46 Linienpaaren pro Millimeter) die Beugungsbegrenzung. Das heißt das immer feinere Strukturen deswegen mit zunehmend geringerem Kontrast abgebildet werden (zusätzliche Verringerung durch die (bei großen Ortsfrequenzen sehr wahrscheinlichen) Objektivfehler insbesondere in den Bildecken natürlich nicht ausgeschlossen). Dies bedeutet einen Verlust an Bildqualität allein durch die Beugungsbegrenzung der Objektivblende und nicht durch den Bildsensor. Dieser Effekt ist in den Rohdatenaufnahmen meistens deutlicher nachzuvollziehen als in den vom Kameragehäuse "entwickelten" JPEG-Dateien, da die (äußerst leistungsfähigen) Bildprozessoren eine Menge Bilddatenverarbeitung durchführen, wie zum Beispiel Anti-Aliasing, Rauschunterdrückung, Weißabgleich und eine ortsfrequenzabhängige Erhöhung des Kontrastes. Wenn bei sehr hohen Ortsfrequenzen der Kontrast künstlich zu stark erhöht wird oder durch Pixelfehler (siehe auch Hotpixel) sowie das Aliasing Artefakte scheinbar hervorgerufen wird, kann sogar ein Bildkontrast ermittelt (und gegebenenfalls bewertet) werden, der der Bildqualität gar nicht zuträglich ist. --Bautsch10:33, 17. Jan. 2020 (CET)
Zitat: "deren Durchmesser wird größer, und dadurch die Überlappung stärker" - genau das meinte ich damit, habe es nur unglücklich formuliert.
Du meinst mit Deiner Ausführung also, dass über die 46 lp/mm hinaus durchaus Bildinformationen erfaßt werden können, jedoch mit zunehmendem Verlust an Bildqualität, wie Kontrastverlust, etc; zusammengenommen gehen bei F8 über die 46 lp/mm hinaus mehr und mehr Details verloren. Das erklärt warum der Grauring beim Siemensstern nicht schlagartig, sondern mit einem "weichen Übergang" in Erscheinung tritt. Allerdings titt er in Erscheindung, was bedeutet, dass der bei Blende F8 im Vergleich zur Blende F4 früher einsetzende Detailverlust messbar sein sollte.
Wenn ich Dich richtig verstanden habe, dann schreibst Du dass der Detailverlust im Testlabor erst bei mehr als 90 lp/mm gemessen werden konnte, weil die Auswirkungen der Beugung aus dem Bild bereits in der Kamera herausgerechnet wurde. Das ein moderner Bildverarbeitungsprozessor aus den Informationen, die über die 46 lp/mm hinaus vom Sensor erfaßt werden, eine solch hohe Bildauflösung errechnen kann, hätte ich nicht für möglich gehalten. Das Messergebnis ist schließlich doppelt so hoch, als es die Optik eigentlich her gibt. Wow. Gruß, -- ηeonZERO14:02, 17. Jan. 2020 (CET)
Ganz so euphorisch würde ich das nicht sehen: bei dem, was "die Optik hergibt" (sprich ohne Beugungsbegrenzung) werden im Idealfall über 90 Prozent Kontrast gemessen, die Messergebnisse bei größeren Ortsfrequenzen ergeben zunehmend weniger Kontrast. Die eigentliche Frage ist, welche Kontraste bei welchen Ortsfrequenzen werden wie bewertet, um eine Bildqualität zu ermitteln. Und wer hierbei nach weniger nutzwertigen, aber möglichst hohen Zahlen giert, ist aus meiner Sicht schlechter beraten, als jemand der einfach nur die nützlichen Ortsfrequenzbereiche und deren Modulationübertragungen bewertet. Erstere könnten statt einer Messung im Prinzip auch einfach nur die Pixel auf dem Bildsensor zählen (oder deren Anzahl ausrechnen), letztere messen die tatsächliche Kontrastübertragung bei allen Ortsfrequenzen und bewerten die wichtigen. --Bautsch13:50, 18. Jan. 2020 (CET)
Zitat: "bei dem, was "die Optik hergibt" (sprich ohne Beugungsbegrenzung) werden im Idealfall über 90 Prozent Kontrast gemessen". Ich lese mir den Testbericht gerade noch einmal durch und die schreiben dort, Zitat "Die höchste Auflösung erreicht die Sony [...] bei 50 Prozent Kontrast mit [...] 101,6 lp/mm bei F4 [...]".1 Leider schreiben sie an der Stelle, an der die Auflösung von 90 lp/mm bei F8 erwähnt wird, nichts von dem Kontrast, aber ich gehe jetzt einmal davon aus, dass auch dort die 50% gemeint sind. Bedeutet das jetzt, dass das Testlabor bei Ihrer Messung einfach nur den Schwellwert runter setzte, indem sie statt der 90% eine 50%-Kontrastvorgabe nutzen, und das nur, um im Ergebnis mehr lp/mm zu erhalten? Gruß, -- ηeonZERO18:11, 20. Jan. 2020 (CET)
Der Schwellwert für den Kontrast ist mehr oder weniger willkürlich, und ich habe auch schon häufig gesehen, dass ausschließlich die Ortsfrequenz bei der 10-Prozent-Kontrastschwelle bewertet wurde. Und klar: je geringer der Schwellwert, desto größer die entsprechende Ortsfrequenz, aber gleichzeitig mit schnell sinkender Aussagekraft. Wichtig wäre aus meiner Sicht, die gesamte Kontrastübertragungsfunktion zu messen und in einem sinnvollen Bereich (also zum Beispiel entsprechend der Kontrastempfindlichkeitsfunktion (auch "CSF" abgekürzt für "Contrast Sensitivity Function") des menschlichen Auges) zu bewerten. Dieses Vorgehen spiegelt sich übrigens auch in der Heynacher-Zahl aus den 1970er Jahren wider, die nach dem Carl-Zeiss-Mitarbeiter Erich Heynacher benannt wurde. Bei heutigen hochwertigen Digitalkameras mit 20 Megapixel und aufwärts ist jedoch in der Regel schon das Objektiv der auflösungsbegrenzende Faktor und nicht erst die Bildauflösung des Bildsensors. Im englischsprachigen Raum hat sich für das intensive Betrachten der einzelnen Bildpunkte übrigens bereits der Begriff "Pixel Peeping" etabliert... --Bautsch10:03, 21. Jan. 2020 (CET)
"Pixel Peeping" habe ich eine Zeit lang belächelt, aber damit habe ich es mir zu einfach gemacht. Gleichauf war ich 10 Jahre lang der festen Meinung, bei gleich großer Sensorfläche wäre eine niedrige Sensorauflösung einer hohen Sensorauflösung unter ungünstigen Lichtbedingungen generell überlegen. Damit lag ich falsch. Denn die Pixel sind zwar kleiner und somit rauschempfindlicher, je höher ein Bildsensor auflöst. Dennoch weisen Vergleichstests darauf hin, dass trotz stärkerer Rauschunterdrückung bei hohen ISO-Werten das hochauflösende Foto mehr Details enthalten kann, vor allem (aber nicht nur) wenn es auf die gleiche Ausgabegröße (z.B. A3-Ausdruck) verkleinert wird. Das gilt eigenartigerweise auch für Kamerasensoren, die weit über die von Dir angesprochenen 20 Megapixel hinaus gehen.
Als Beispiel lieferte mit Stand Februar 2018 bei einem High-ISO-Auflösungs-Vergleich mit ISO 51.200 die jeweils höher auflösende Kamera die besseren Bilder.2 Verglichen wurden die Sony Alpha 7S II (12 Megapixel) mit einer Sony Alpha 9 (24 Megapixel) und Sony Alpha 7R III (42 Megapixel). Die jeweils höher auflösende Kamera zeigt zwar ein aggressiveres Rauschen, enthält aber deutlich mehr Details und das Rauschen ist feinkörniger und damit weniger störend, wobei das Bild insgesamt deutlich schärfer wirkt. Das gilt sowohl auf Pixelebene (das angesprochene "Pixel Peeping") als auch für die auf gleicher Ausgabegröße verkleinerten Fotos; innerhalb dieses Tests war es für das Ergebnis unerheblich, ob für den Vergleich das Bild der hochauflösenden Kameras runter oder das der niedrigauflösenden Kameras hochskaliert wurde. Siehe deren Testfotos; das ist einen Blick wert (Java-Script muss aktiviert sein).
Als weiteres Beispiel wurden 2017 in einem Testlabor1 eine 24 MP und 42 MP Kamera miteinander verglichen. Die 24 Megapixel-Kamera war der 42 Megapixel-Kamera beim Signal-Rauschverhalten deutlich überlegen. Trotzdem liefert das auf gleicher Ausgabegröße verkleinerte Foto der 42 Megapixel-Kamera mehr Details, trotz stärkerer Rauschunterdrückung – Zitat: „Hier können die hochauflösenden Kleinbildsensoren tatsächlich von ihrer höheren Auflösung profitieren trotz kleinerer [rauschempfindlicher] Pixel bei hohen ISO“. Bis ISO 12.800 liefert die 42 MP auflösende A7 R II eine mehr als brauchbare Bildqualität mit nur geringem Detailverlust, bei der A7 II mit 24 Megapixel Bildsensor liegt die Grenze hingegen bei ISO 3.200. Diese Aussage steht im absoluten Widerspruch zu meinem gut 10 Jahre andauernden Irrtum.
Damit will ich darauf hinaus, dass ich es mir seither nicht mehr so einfach mache, indem ich hohe Sensorauflösungen von weit über 20 MP heute nicht mehr generell belächle.
Zurück zum Thema, Zitat: "Der Schwellwert für den Kontrast ist mehr oder weniger willkürlich". Unter solchen Bedingungen taugen die ermittelten Werte nicht einmal mehr für einen Vergleich zwischen zwei Objektiven, die an der gleichen Kamera getestet wurden, wenn das eine Objektiv mit dem einen und das anderen mit einem anderen Schwellwert gemessen wurde. Gibt es einen Grund dafür, warum die Testlabore keinen einheitlichen Schwellwert verwenden?
Zitat: "ich habe auch schon häufig gesehen, dass ausschließlich die Ortsfrequenz bei der 10-Prozent-Kontrastschwelle bewertet wurde [...] je geringer der Schwellwert, desto größer die entsprechende Ortsfrequenz, aber gleichzeitig mit schnell sinkender Aussagekraft". Wenn doch die Aussagekraft sinkt, warum geht dann überhaupt jemand mit dem Schwellwert so weit runter? Auch das ergibt für mich derzeit überhaupt keinen Sinn... *grübel* Gruß, -- ηeonZERO11:28, 22. Jan. 2020 (CET)
Beide gezeigten ISO-51200-Bilder sind für eine hochwertige großformatige Ausgabe offensichtlich nicht geeignet. Das alpha-7R-Bild hat im Histogramm deutliche hellere Anteile und eine höhere Farbsättigung, was auf eine rechnerische Kontrastanhebung hindeutet. Ferner zeigt es mehr sichtbares Luminanzrauschen. Die für professionelle Anwender konzipierte alpha 9 ist vermutlich weniger aggressiv abgestimmt. Wird das in den beiden Ausschnitten angeglichen, ist der Unterschied geringer. Die alpha 9 hat vermutlich einen optischen Tiefpass vor dem Bildsensor, um hässliche optische Aliasing-Effekte zu vermeiden. Bei Bayer-Sensoren mit sehr hoher Bildauflösung, kann diese Filterung mit der Firmware (für JPEG-Dateien) oder per Software (mit Rohdatendateien) durchgeführt werden. Das kann aber halt auch zu Artefakten führen, die bei einer photographischen Dokumentation nicht erwünscht sind. Wie auch immer, werden all diese Einflussfaktoren berücksichtigt, ist es nicht erstaunlich, dass mit der 7R III und demselben hochwertigen Objektiv eine etwas höhere Detailauflösung erreicht werden kann. Das kann bei einigen Kameras im Bedarfsfall übrigens auch mit Pixel shift realisiert werden (siehe zum Beispiel das mit einem Zoomobjektiv und einem 20-Megapixel-Bildsensor aufgenommene 80-Megapixel-Bild Datei:Berliner.Philharmonie.von.Sueden.jpg).
Orionnebel
Die Frage bleibt allerdings: "Für welche Bildausgabe spielt eine Auflösung von über 20 Megapixel eine praktische Rolle ?" Ein Fall wäre eine sehr großformatige Ausgabe eines mit niedrigem Belichtungsindex aufgenommenen Bildes, das - aus welchen Gründen auch immer - aus so geringem Betrachtungsabstand angesehen wird, dass das gesamte Bild gar nicht mehr vollständig erfasst werden kann, ohne den Kopf oder die Augäpfel zu bewegen (i.e. "Pixel Peeping"). Die bessere Wahl sind in diesem Bedarfsfall immer photographische Detailaufnahmen der betreffenden Objekte mit entsprechend hoher Kontrastübertragung durch die Verwendung von längeren Brennweiten, kürzeren Objektweiten oder Makroobjektiven. Das 324-Megapixel-Bild rechts wurde zum Beispiel aus 520 Einzelaufnahmen zusammengesetzt und kann gut zum Hineinzoomen genutzt werden. Der Betrachter wird jedoch nie viel mehr als zwei Millionen Bildpunkte gleichzeitig wahrnehmen. --Bautsch12:57, 24. Jan. 2020 (CET)
Dass ISO-51200'er Bilder für eine hochwertige großformatige Ausgabe nicht geeignet sind, sollte klar sein (jedenfalls nicht mit derzeitigen Kameras). Mit der 12 MP auflösdenden A7S sind bei ISO 800 hochwertige Fotos drin (noch gerade so). Wir reden hier von Ausgaben auf großem Format und da liefert ISO 1600 je nach Situation vermehrt Fotos, die in Bezug auf Hochwertigkeit an ihre Grenzen gelangen, finde ich. Und wenn - auf die gleiche Ausgabegröße bezogen - eine Kamera mit 24 MP oder 42 MP ebenfalls bei ISO 800 oder sogar bei ISO 1600 trotz oder sogar dank der höheren Auflösung vergleichbar hochwertige Bilder liefert, dann ist das bemerkenswert. So bemerkenswert, dass es mich dazu veranlaßt hat, meinen o.g. Standpunkt zu überdenken. Dabei spielt es keine Rolle, ob dank der hohen Auflösung der Tiefpass-Filter weggefallen ist und dass der Rauschfilter effizienter funktioniert, weil pro Flächenabschnitt mehr benachbarte Bildpunkte zur Denoise-Berechnung herangezogen werden können; ebenso um die Auswirkungen der Beugung aus einem Bild herauszurechnen - oder was auch immer. Das Ergebnis zählt. Und wenn das Ergebnis so ist, wie gerade beschrieben, dann stimmt m.E. die Aussage nicht, dass bei gleich großer Sensorfläche eine niedrige Sensorauflösung einer hohen Sensorauflösung unter ungünstigen Lichtbedingungen generell überlegen ist. In diesem Kontext scheinen auch die 42 MP durchaus eine Daseinsberechtigung zu haben.
Mehr habe ich damit nicht zum Ausdruck bringen wollen.
Zurück zum Thema: Gibt es einen Grund dafür, warum die Testlabore keinen einheitlichen Schwellwert verwenden? Welche Gründe gibt es überhaupt, mit dem Schwellwert so weit runter zu gehen, wenn die Aussagekraft doch dabei abnimmt? Gruß, -- ηeonZERO19:16, 24. Jan. 2020 (CET)
Es sind ja die Auswertenden der Ergebnisse der Testlabore und nicht die Testlabore selbst, die die Bewertungsmaßstäbe festlegen. In der Norm ISO 12233 wird beschrieben, wie das Auflösungsvermögen in verschiedenen radialen und tangentialen Richtungen und an verschiedenen Bildorten (und natürlich bei verschiedenen Belichtungsindizes, -zeiten und Blendenzahlen) gemessen werden kann, und es wird nur erwähnt, dass die Ortsfrequenz zum Beispiel bei 10 Prozent Modulation ermittelt und dargestellt werden kann. Es wird in dieser Norm auch explizit auf die Gefahr von Aliasing-Effekten zwischen halber und voller Nyquist-Frequenz des Bildsensors aufmerksam gemacht, und dadurch können leicht schenbare Modulationen von über 10 Prozent auftreten. Wie aus den zahlreichen Messwerten eine Beurteilung der Qualität gewonnen wird, ist normativ allerdings nicht festgelegt. Manchen scheinen möglichst wenige und große Messwerte wichtig zu sein. Wer da welche Motivation hat, kann ich allerdings nicht beantworten. --Bautsch11:38, 25. Jan. 2020 (CET)
Noch ein Nachsatz: Mit einem einzelnen Schwellwert ist eine objektive Beurteilung jedenfalls nicht möglich, da hierfür mehrere (sinnvolle) Ortsfrequenzen, Modulationen, Richtungen und Bildorte berücksichtigt werden müssen. --Bautsch11:44, 25. Jan. 2020 (CET)
Schon klar: Wird die Auflösung z.B. in vertikaler Richtung und in der Diagonalen erfaßt, dann wird jeweils ein anderes Ergebnis dabei herauskommen. Und dass man jeden Bereich des Bildes separat betrachten muss, um eine Optik richtig bewerten zu können, ist auch klar; jeweils im Einflussbereich der Blende.
Doch um das Zusammenspiel von Optik und Sensorik vergleichbar darzustellen, muss der auswertende Bericht nicht jeden ermittelten Wert darlegen. Eine einheitliche Messrichtung (z.B. die Vertikale) mit einheitlichem Schwellwert für den Kontrast sollten genügen, gekoppelt mit der Aussage bei welcher Blende innerhalb der Bildmitte die maximale Auflösung erzielt werden konnte und wie hoch sie ist; gleiches für den Bildrand.
Dank solcher Eckdaten ist eine erste Einschätzung möglich. Klar wäre die Aussagekraft wesentlich größer, wenn die Heynacher-Zahl die Daten für den Vergleich ergänzt, was leider nicht üblich ist (warum eigentlich?). Aber gänzlich ungeeignet ist das ganze Konstrukt, wenn der Schwellwert für den Kontrast willkürlich festgelegt wird.
Es ist unbestritten, dass für eine umfassende Einschätzung der Optik im Zusammenspiel mit der jeweiligen Kamera die genannten Eckdaten nicht genügen. Es sind eben nur Eckdaten. Aber darum soll es hier nicht gehen.
Es geht mir einzig und allein um eine vergleichbare Erfassung/Darstellung solcher Eckdaten. Sie könnten wie eine Art Index genutzt werden, anhand derer die Objektive und Kameras herausgefunden werden, die es je nach Anspruch und Geldbörse Wert sind, weiter betrachtet zu werden. Doch die Tester scheinen alles daran zu setzen, ihre Eckdaten nicht vergleichbar zu machen. Das ist es, was ich nicht verstehe. Gruß, -- ηeonZERO21:52, 25. Jan. 2020 (CET)
Könnte es so einfach sein?: Aus der bisherigen Diskussion geht hervor, dass bei F8 über die 46 lp/mm hinaus mehr und mehr Details verloren gehen, weil der Kontrast sinkt. Mehr als 46 lp/mm sind also mit 100% Kontrast nicht drin, selbst bei einer fehlerfreien Optik in Kombination mit einem hervorragenden Sensor. Ist die Sensorauflösung höher, können über die 46 lp/mm hinaus durchaus Bildinformationen erfaßt werden, jedoch mit zunehmendem Verlust an Bildqualität. So wurden im o.g. Testlabor bei 50% Kontrast 90 lp/mm gemessen. Doch, Zitat: "Eine Modulation von 50 Prozent erzeugt ein als ziemlich flau empfundenes Bild, denn Schwarz hat dann nicht mehr die Leuchtdichte 0 (das wären 100 Prozent Kontrast), sondern ein Drittel der hellsten Leuchtdichte".
Um also zu wissen, wie nahe die getestete Kombination von Optik und Sensorik an die maximal mögliche optische Auflösung heran reicht, benötigt man die Angabe der gemessenen Auflösung bei 100% Kontrast. Leider zitiert der Testbericht nur die Daten, die bei 50% Kontrast gemessenen wurden. Lassen sich daraus die Daten für 100% berechnen? Beispielsweise mit der folgenden Gleichung...
... die die Auflösungsangaben bei 50% ins Verhältnis zu 100% setzt. Wenn diese Formel falsch ist, gibt es eine andere Möglichkeit das entsprechend umzurechnen? Oder ist das gänzlich unmöglich? Gruß, -- ηeonZERO11:54, 29. Jan. 2020 (CET)
Vergleich der Modulationsübertragungsfunktionen von zwei verschiedenen Objektiven mit demselben Bildsensor. Bei der Ortsfrequenz null haben alle Objektive die maximale Kontrastübertragung von 100 Prozent, und bei der maximal dargestellten Ortsfrequenz haben beide hier dargestellten Objektive eine Kontrastübertragung von zirka zehn Prozent. Dennoch ist das blau dargestellte Objektiv deutlich besser als das dunkelgelb dargestellte, da es alle mittleren Ortsfrequenzen besser überträgt.
So einfach ist es leider nicht. Die Kontrastübertragung beträgt bei allen Objektiven theoretisch und praktisch nur bei der Ortsfrequenz null 100 Prozent und nimmt dann streng monoton fallend ab (siehe auch das Diagramm rechts mit zwei Beispiel-Objektiven). Der Verlauf der Kontrastübertragungskurve kann jedoch mehr oder weniger steil sein, und das Gefälle kann sich an jeder Stelle stark ändern (und natürlich kann der Kurvenverlauf auch durch digitale Bildbearbeitung verändert werden, was regelmäßig bei der nachträglichen Schärfung von Bildern passiert, wodurch dann bei höheren Ortsfrequenzen eine Kontrastübertragung von 100 Prozent oder gar höher auftreten kann (das heißt, dass das Bild dann mehr Kontrast hat als das Original). Es sollte aber nicht außer Betracht fallen, dass hierbei auch der Kontrast des Bildrauschens verstärkt wird und es dadurch deutlicher sichtbar werden kann).
Unter Optikern ist es daher üblich, mehrere Kontrastübertragungen in einem zweckmäßigen Ortsfrequenzbereich zu betrachten und zusammenzufassen (sei es per Summenformel oder per Integralrechnung). Dies führt dann auch zu der aussagekräftigen und oben bereits erwähnten Heynacher-Zahl. --Bautsch13:36, 29. Jan. 2020 (CET)
Verstehe, meine Gleichung würde nur funktionieren, wenn der Verlauf linear wäre, was er nicht ist.
Ich denke ich lag die ganze Zeit falsch mit meiner Vermutung, dass ein Vergleich der ermittelten Auflösungswerte bei 100% Kontrast am sinnvollsten ist. Darüber musste ich erst einmal "eine Nacht schlafen": Mir wird jetzt erst so richtig klar, dass zwei Objektive trotz gleichem Ausgangs-Auflösungsvermögen (sowohl bei 100% als auch bei 10% Kontrast) deutlich von einander abweichen können, wenn es um die Werte dazwischen geht. Ich weiß, Du hast weiter oben häufig über den Kontrast geschrieben und ich wollte später in einem separaten Abschnitt darauf näher eingehen, weil ich diese Themen nicht miteinander vermischen wollte. Denn ich ging davon aus, dass sich dies keinesfalls auf den selben Bildbereich bezog. Hier hätte ich einen linearen Verlauf erwartet, zumindest wenn er in Relation zum Vergleichsobjektiv gesetzt wird. Doch jetzt erkenne ich meinen Irrtum, der besonders deutlich anhand der Grafik zu erkennen ist. Du hast auf diese Grafik schon früher hingewiesen, aber da hat es bei mir leider noch nicht "klick" gemacht (ich habe die Grafik schlicht fehlinterpretiert).
Deine Grafik liefert die Erklärung dafür, warum die o.g. Tester (wie zahlreiche andere auch) ihre Auflösungswerte bei 50% Kontrast wählen: An dieser Stelle sind die Qualitätsunterschiede zwischen den Objektiven am deutlichsten erkennbar. Wenn man also schon die Heynacher-Zahl nicht in den Testbericht einbezieht, dann sollten wenigstens die Kontrastangaben bei 50% liegen. Oder sehe ich das falsch?
Man muss also die Testberichte vollkommen anders bewerten, als ich zunächst angenommen hatte: Wir kennen die Formel für die Berechnung der maximalen optischen Auflösung, also für die Auflösung, die bei 100% Kontrast maximal erfasst werden kann. Es muss doch auch eine Formel geben für die maximal mögliche Auflösung bei 50% Kontrast. Dann ließe sich der gemessene Wert in Relation dazu setzen und man kann erkennen, wie nahe ein Objektiv jeweils an das Optimum heran reicht... Das ist zumindest dann interessant, wenn es nicht darum geht zwei Objektive miteinander zu vergleichen, sondern ganz allgemein die Effektivität einer Kamera-/Objektiv-Kombination grob einzuschätzen. Gruß, -- ηeonZERO16:48, 30. Jan. 2020 (CET)
Die Ortsfrequenz bei einer Kontrastübertragung von 50 Prozent ist im Gegensatz zu den Ortsfrequenzen bei einer Kontrastübertragung von 100 oder 10 Prozent zumindest ein gewisser Indikator für das Auflösungsvermögen einer Kamera. Nichtsdestoweniger können zwei optische Abbildungen mit der gleichen Ortsfrequenz bei 50 Prozent Kontrastübertragung deutlich anders aussehen beziehungsweise vom Bildsensor aufgenommen werden, je nachdem wie gut die Objektkontraste bei den geringeren Ortsfrequenzen übertragen werden. --Bautsch17:29, 30. Jan. 2020 (CET)
Wie Du geschrieben hast wäre die Heynacher-Zahl ein geeigneter Wert, um solche Unterschiede vergleichbar darzustellen, aber die wird in den Testberichten der Verbraucherzeitschriften/Onlineportalen für gewöhnlich nicht erwähnt. Als Leser von solchen Berichten muss man sich an dem orientieren, was dort verfügbar ist. Und das sind in der Regel einzig die Ortfrequenzen in "xxx lp/mm bei 50 Prozent Kontrast". Leider.
Wenn die Blende bekannt ist, nehmen wir z.B. die Eingangs erwähnte F8, wie läßt sich die dazu passende maximale Ortsfrequenz berechnen bei einer Kontrastübertragung von 50 Prozent? Gruß, -- ηeonZERO22:41, 30. Jan. 2020 (CET)
Der theoretisch maximale Wert für die Ortsfrequenz bei einer Modulation von 50 Prozent liegt irgendwo zwischen den Kehrwerten des Durchmessers und des Radius des Beugungsscheibchens, wo die beugungsbegrenzte Modulation 90 beziehungsweise 1 Prozent beträgt (siehe Diagramme oben). Ich habe diese Ortsfrequenz noch nicht ausgerechnet, und finde sie auch nicht interessant, denn das Auflösungsvermögen ist bei der Verwendung von heutigen Bildsensoren in der Regel und in den Bildecken sowieso durch die Objektivfehler begrenzt und nicht durch Beugung oder Pixelzahlen (siehe übrigens auch kritische Blende). --Bautsch21:20, 31. Jan. 2020 (CET)
Quellenangabe: Zweifel an Sinnhaftigkeit
Letzter Kommentar: vor 3 Jahren1 Kommentar1 Person ist an der Diskussion beteiligt
Im Abschnitt Speichermedien dient eine Panasonic-Bedienungsanleitung von 2008 als Quelle für eine hinzugefügte Aussage. Ich habe zwar Änderungen vorgenommen, damit der Artikel nicht mehr in der Wartungskategorie Vorlagenfehler aufscheint. ;-) Ich hege jedoch Zweifel, ob diese Quelle geeignet ist, die Aussage zu stützen. Bitte um Überprüfung. --sammy (Diskussion) 14:56, 10. Apr. 2021 (CEST)




 17:34, 31. Jan. 2012 (CET)
17:34, 31. Jan. 2012 (CET)


















.plus.I(x%2B1).png)
.plus.I(x%2B1).jpg)
.plus.I(x%2B0.5).png)
.plus.I(x%2B0.5).jpg)
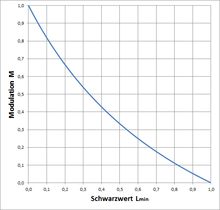



{kind=link}
{kind=link}
{kind=link}
{kind=link}