Dies ist eine alte Version dieser Seite, zuletzt bearbeitet am 15. Oktober 2016 um 21:04 Uhr durch JonskiC(Diskussion | Beiträge). Sie kann sich erheblich von der aktuellen Version unterscheiden.
Das einfache lineare Regressionsmodell geht von zwei metrischen Größen aus: einer Einflussgröße und einer Zielgröße . Es liegen Paare von Messwerten vor, die in einem funktionalen Zusammenhang stehen, der sich aus einem systematischen und einem stochastischen Teil zusammensetzt:
Beispiel einer Regressionsgerade einer linearen Einfachregression, die durch die Punktwolke der Messung gelegt wird
Die einfache lineare Regression versucht, statt mit einer beliebigen Anzahl von Parametern, einen linearen Zusammenhang zwischen der Einfluss- und der Zielgröße mithilfe von zwei linearen Parametern und herzustellen (). Aus diesem Grund wird die Regressionsfunktion wie folgt spezifiziert:
Daraus ergibt sich das einfache lineare Regressionsmodell:[1]
Bildlich gesprochen wird eine Gerade durch die Punktwolke der Messung gelegt.
In der gängigen Literatur wird die Gerade oft durch den Achsenabschnitt und die Steigung beschrieben. Die abhängige Variable (in diesem Kontext oft auch endogene Variable genannt) kann dadurch in Abhängigkeit vom Regressor (oft auch exogene Variable genannt) , bei oben genannter Notation, wie folgt dargestellt werden:
Dabei ist ein additiver stochastischer Fehlerterm, der Abweichungen vom idealen Zusammenhang – also der Geraden – achsenparallel misst. Im Gegensatz zur exogenen und endogenen Variablen ist die Zufallskomponente nicht direkt beobachtbar. Ihre Realisationen sind nur indirekt über die Regression beobachtbar und heißen Residuen.
Modellannahmen
In Bezug auf den Fehlerterm werden folgende Annahmen getroffen:[2]
Die Fehlerterme sind unabhängig: sind voneinander unabhängige Zufallsvariablen.
Aus der Normalverteilung der Fehlerterme folgt, dass auch normalverteilt ist:
Die Verteilung der hängt also von der Verteilung der Fehlerterme ab. Der Erwartungswert der abhängigen Variablen, bei gegebenen Daten lautet:
Für die Varianz der abhängigen Variablen gilt:
Damit ergibt sich für die Verteilung der abhängigen bzw. endogenen Variablen:
Da aufgrund der Annahme, dass die Fehlerterme im Mittel null sein müssen, der bedingte Erwartungswert von () dem wahren Modell
entspricht, stellen wir mit der Annahme über die Fehlerterme die Forderung, dass unser Modell im Mittel korrekt sein muss.
In Bezug auf die exogene Variable werden folgende Annahmen getroffen:[2]
Die exogene Variable kann wie in einem Experiment kontrolliert werden und ist damit keine Zufallsvariable (Exogenität der Regressoren).
Die exogene Variable weist bzgl. aller Beobachtungen nicht den gleichen Wert auf. Dies impliziert, dass die Variation der exogenen Variablen positiv sein muss: .
Schätzung der Regressionskoeffizienten
Um nun die Parameter der Gerade zu bestimmen, wird die Summe der quadrierten Fehlerterme mittels der Methode der kleinsten Quadrate minimiert.[3]
Dabei ist der Vektor der -dimensionaleEinsvektor. Für einen Vektor ist also die Summe seiner Komponenten. Des Weiteren ergibt sich die zweite Gleichheit, bei der Berechnung von , durch Anwenden des Verschiebungssatzes.
Erwartungstreue des Kleinste-Quadrate-Schätzers
Für die Regressionsgleichung lässt sich zeigen, dass die Schätzer für und für erwartungstreu sind, das heißt, es gilt und . Der Kleinste-Quadrate-Schätzer schätzt also die wahren Werte der Koeffizienten „im Mittel richtig“. Das folgt aus der Linearität des Erwartungswerts und der Voraussetzung . Damit folgt nämlich
und
.
Als Erwartungswert von ergibt sich daher:
Für den Erwartungswert von erhält man schließlich:[4]
Beispiel
Im Folgenden wird die einfache lineare Regression anhand eines Beispiels dargestellt.
Eine renommierte Sektkellerei möchte einen hochwertigen Rieslingsekt auf den Markt bringen. Für die Festlegung des Abgabepreises soll zunächst eine Preis-Absatz-Funktion ermittelt werden. Dazu wird in Geschäften ein Testverkauf durchgeführt und man erhält sechs Wertepaare mit dem jeweiligen Ladenpreis einer Flasche (in Euro) sowie der Zahl der jeweils verkauften Flaschen :
Geschäft
1
2
3
4
5
6
Flaschenpreis
20
16
15
16
13
10
verkaufte Menge
0
3
7
4
6
10
In Matrixform kann das Beispiel verallgemeinert wie folgt dargestellt werden:
Betrachtet werden zwei Variablen und , die vermutlich ungefähr in einem linearen Zusammenhang
stehen. Auf die Vermutung, dass es sich um einen linearen Zusammenhang handelt, kommt man, wenn man das obige Streudiagramm betrachtet. Dort erkennt man, dass die eingetragenen Datenpunkte nahezu auf einer Linie liegen. Im Weiteren sind als unabhängige und als abhängige Variable definiert. Es existieren von und je Beobachtungen und , wobei von bis geht. Der funktionale Zusammenhang zwischen und kann nicht exakt festgestellt werden, da von einer Störgröße überlagert wird. Diese Störgröße ist als Zufallsvariable (der Grundgesamtheit) konzipiert, die nicht direkt erfassbare Einflüsse (unbeobachtete Heterogenität, menschliches Verhalten oder Messungenauigkeiten oder Ähnliches) darstellt. Es ergibt sich also das Modell
oder genauer
Da und nicht bekannt sind, kann nicht in die Komponenten und zerlegt werden. Des Weiteren soll eine mathematische Schätzung für die Parameter und durch und gefunden werden, damit ergibt sich
mit dem Residuum der Stichprobe. Das Residuum gibt die Differenz zwischen den Messwerten und der Regressionsgerade an. Des Weiteren bezeichnet man mit den Schätzwert für . Es gilt
und somit kann man das Residuum schreiben als .
Es gibt verschiedene Möglichkeiten, die Gerade zu schätzen. Man könnte eine Gerade so durch die Punktwolke legen, dass die Quadratsumme der Residuen, also der senkrechten Abweichungen der Punkte von dieser Ausgleichsgeraden minimiert wird. Trägt man die wahre unbekannte und die geschätzte Regressionsgerade in einer gemeinsamen Grafik ein, dann ergibt sich folgende Abbildung.
Für das folgende Zahlenbeispiel ergibt sich und . Somit erhält man die Schätzwerte für und durch einfaches Einsetzen in obige Formeln. Zwischenwerte in diesen Formeln sind in folgender Tabelle dargestellt.
Flaschenpreis
verkaufte Menge
1
20
0
5
−5
−25
25
25
0,09
2
16
3
1
−2
−2
1
4
4,02
3
15
7
0
2
0
0
4
5,00
4
16
4
1
−1
−1
1
1
4,02
5
13
6
−2
1
−2
4
1
6,96
6
10
10
−5
5
−25
25
25
9,91
Summe
90
30
0
0
−55
56
60
30,00
Es ergibt sich in dem Beispiel
und .
Die geschätzte Regressionsgerade lautet somit
,
sodass man vermuten kann, dass bei jedem Euro mehr der Absatz im Durchschnitt ceteris paribus um ungefähr eine Flasche sinkt.
Bildliche Darstellung und Interpretation
Regressionsgeraden für [rot] und [blau]; hier werden die Parameter und durch und dargestellt
Wie in der statistischen Literatur immer wieder betont wird, ist ein hoher Wert des Korrelationskoeffizienten zweier Zufallsvariablen und allein noch kein hinreichender Beleg für den kausalen (d. h. ursächlichen) Zusammenhang von und , ebenso wenig für dessen mögliche Richtung.
Anders als gemeinhin beschrieben, sollte man es daher bei der linearen Regression zweier Zufallsvariablen und stets mit nicht nur einer, sondern zwei voneinander unabhängigen Regressionsgeraden zu tun haben: der ersten für die vermutete lineare Abhängigkeit , der zweiten für die nicht minder mögliche Abhängigkeit .[5]
Bezeichnet man die Richtung der -Achse als Horizontale und die der -Achse als Vertikale, läuft die Berechnung des Regressionskoeffizienten also im ersten Fall auf das üblicherweise bestimmte Minimum der vertikalen quadratischen Abweichungen hinaus, im zweiten Fall dagegen auf das Minimum der horizontalen quadratischen Abweichungen.
Rein äußerlich betrachtet bilden die beiden Regressionsgeraden und eine Schere, deren Schnitt- und Angelpunkt der Schwerpunkt der untersuchten Punktwolke ist. Je weiter sich diese Schere öffnet, desto geringer ist die Korrelation beider Variablen, bis hin zur Orthogonalität beider Regressionsgeraden, zahlenmäßig ausgedrückt durch den Korrelationskoeffizienten bzw. Schnittwinkel.
Umgekehrt nimmt die Korrelation beider Variablen umso mehr zu, je mehr sich die Schere schließt – bei Kollinearität der Richtungsvektoren beider Regressionsgeraden schließlich, also dann, wenn beide bildlich übereinander liegen, nimmt je nach Vorzeichen der Kovarianz den Maximalwert oder an, was bedeutet, dass zwischen und ein streng linearer Zusammenhang besteht und sich (wohlgemerkt nur in diesem einen einzigen Fall) die Berechnung einer zweiten Regressionsgeraden erübrigt.
Wie der nachfolgenden Tabelle zu entnehmen, haben die Gleichungen der beiden Regressionsgeraden große formale Ähnlichkeit, etwa, was ihre Anstiege bzw. angeht, die gleich den jeweiligen Regressionskoeffizienten sind und sich nur durch ihre Nenner unterscheiden: im ersten Fall die Varianz von , im zweiten die von :
Regressionskoeffizient
Korrelationskoeffizient
Regressionskoeffizient
Empirischer Regressionskoeffizient
Empirischer Korrelationskoeffizient
Empirischer Regressionskoeffizient
Regressionsgerade
Bestimmtheitsmaß
Regressionsgerade
Zu erkennen ist außerdem die mathematische Mittelstellung des Korrelationskoeffizienten und seines Quadrats, des sogenannten Bestimmtheitsmaßes, gegenüber den beiden Regressionskoeffizienten, dadurch entstehend, dass man anstelle der Varianzen von bzw. deren geometrisches Mittel
in den Nenner setzt.
Betrachtet man die Differenzen als Komponenten eines -dimensionalen Vektors und die Differenzen als Komponenten eines -dimensionalen Vektors , lässt sich der Korrelationskoeffizient schließlich auch als Kosinus des von beiden Vektoren eingeschlossenen Winkels interpretieren:
Beispiel in Kurzdarstellung
Für das vorangegangene Sektkellerei-Beispiel ergab sich folgende Tabelle:
Flaschenpreis
verkaufte Menge
1
20
0
5
−5
−25
25
25
0,09
2
16
3
1
−2
−2
1
4
4,02
3
15
7
0
2
0
0
4
5,00
4
16
4
1
−1
−1
1
1
4,02
5
13
6
−2
1
−2
4
1
6,96
6
10
10
−5
5
−25
25
25
9,91
Summe
90
30
0
0
−55
56
60
30,00
Daraus ergeben sich folgende Werte:
Koeffizient
Allgemeine Formel
Wert im Beispiel
Steigung der Regressionsgerade
Achsenabschnitt der Regressionsgerade
Empirische Korrelation
Bestimmtheitsmaß
Die geschätzte Regressiongerade ist mit einem Bestimmtheitsmaß von etwa . Das Bestimmtheitsmaß, das ein Zusammenhangsmaß darstellt, sagt aus, dass der Variation in der abhängigen Variablen durch den Regressor erklärt werden kann. Allerdings hat das im Allgemeinen nur eingeschränkte Aussagekraft, weshalb man das korrigierte Bestimmtheitsmaß
heranziehen sollte.
Multiple lineare Regression
Im Folgenden wird ausgehend von der einfachen linearen Regression die multiple Regression eingeführt. Die Response bzw. endogene Variable hängt linear von mehreren fest vorgegebenen erklärenden Variablen ab:
Regressionsebene, die sich an eine Datenwolke im dreidimensionalen Raum anpasst (Fall K=2)
,
wobei wieder die Störgröße repräsentiert. Also ist eine Zufallsvariable und daher ist als lineare Transformation von ebenfalls eine Zufallsvariable. Liegen für die , unsere Daten, und die endogenen Variablen , Datenpaare vor:
Ferner lässt sich das aus Gleichungen bestehende Gleichungssystem nun kompakter darstellen als
gibt somit die Anzahl der zu schätzenden Parameter an. In der einfachen linearen Regression wurde nur der Fall betrachtet, ausgehend davon wird nun die multiple Regression als Verallgemeinerung dessen mit präsentiert. Wie bei der einfachen linearen Regression ist in Anwendungen meist konstant gleich , woraus sich ergibt, dass im multiplen Fall die erste Spalte der Datenmatrix den Einsvektor der Dimension darstellt.
Als stichprobentheoretischer Ansatz wird jedes Stichprobenelement als eine eigene Zufallsvariable interpretiert und ebenso jedes .
Da es sich hier um ein lineares Gleichungssystem handelt, können die Elemente des Systems in Matrix-Schreibweise zusammengefasst werden. Man erhält den -Spaltenvektor der abhängigen Variablen , den der Störgröße als Zufallsvektor und den -Spaltenvektor der Regressionskoeffizienten :
und
Die Datenmatrix lautet in ausgeschriebener Form:
, wobei
Aufgrund der unterschiedlichen Schreibweisen für lässt sich erkennen, dass sich das Modell auch darstellen lässt als:
mit
Repräsentationen:
sind beobachtete Zufallsvariablen.
sind beobachtbare, nicht zufällige, bekannte Variablen.
Des Weiteren trifft man, wie bereits im Abschnitt zur einfachen linearen Regression erwähnt, dieselben Annahmen. Im Fall der multiplen Regression lauten sie:
, und ,
wobei wir nun, statt nur die Varianzen und Kovarianzen der Fehlerterme einzeln zu betrachten, diese beiden in folgender Varianz- Kovarianzmatrix zusammenfassen:
Somit gilt für
mit .
Schätzung der Regressionskoeffizienten nach der Methode der kleinsten Quadrate
Auch im multiplen linearen Regressionsmodell wird nach der Methode der kleinsten Quadrate minimiert, das heißt, es soll so gewählt werden, dass die euklidische Norm minimal wird. Im Folgenden wird jedoch der Ansatz benutzt, dass das matrizielle quadratische Pendant zur Residuenquadratsumme minimiert wird. Dazu wird vorausgesetzt, dass den Rang hat. Dann ist invertierbar und man erhält als Minimierungsproblem:
Bedingung erster Ordnung (Nullsetzen des Gradienten):
Die partiellen Ableitungen erster Ordnung lauten:
Dies zeigt, dass sich die Bedingung erster Ordnung wie folgt kompakt darstellen lässt:
Da die geschätzte Varianz der KQ-Fehlerterme lautet, gilt für die geschätzte Varianz-Kovarianz-Matrix:
Man erhält mit Hilfe des Kleinste-Quadrate-Schätzers das Gleichungssystem
wobei der Vektor der Residuen und die Schätzung für ist. Das Interesse der Analyse liegt vor allem in der Schätzung oder in der Prognose der abhängigen Variablen für ein gegebenes Tupel von .
Diese berechnet sich als
.
Eigenschaften des Kleinste-Quadrate-Schätzers
Erwartungstreue
Im multiplen Fall kann man ebenfalls zeigen, dass der Kleinste-Quadrate-Schätzer erwartungstreu ist. Dies gilt allerdings nur, wenn die Annahme der Exogenität der Regressoren gegeben ist. Wenn man also davon ausgeht, dass die exogenen Variablen keine Zufallsvariablen sind, sondern wie in einem Experiment kontrolliert werden können, gilt bzw. und damit
Falls die Exogenitätsannahme nicht zutrifft, , ist der Kleinste-Quadrate-Schätzer nicht erwartungstreu, sondern verzerrt (englisch: biased), d. h., im Mittel weicht der Parameterschätzer vom wahren Parameter ab:
Der Erwartungswert des Parameterschätzers für ist also nicht gleich dem wahren Parameter.
Effizienz
Der Kleinste-Quadrate-Schätzer ist linear:
Nach dem Satz von Gauß-Markow ist der Schätzer , BLUE (Best Linear Unbiased Estimator), das heißt, er ist derjenige lineareerwartungstreue Schätzer, der unter allen linearen erwartungstreuen Schätzern die kleinste Varianz bzw. Varianz-Kovarianz-Matrix besitzt. Für diese Eigenschaften der Schätzfunktion braucht keine Verteilungsinformation der Störgröße vorzuliegen.
Konsistenz
Der KQ-Schätzer ist unter den bisherigen Annahmen unverzerrt , wobei die Stichprobengröße keinen Einfluss auf die Unverzerrtheit hat (schwaches Gesetz der großen Zahlen). Ein Schätzer ist genau dann konsistent, wenn er in Wahrscheinlichkeit gegen den wahren Wert konvergiert. Die Eigenschaft der Konsistenz bezieht also das Verhalten des Schätzers mit ein, wenn die Anzahl der Beobachtungen größer wird.
Für die Folge gilt, dass sie in Wahrscheinlichkeit gegen den wahren Wert konvergiert
Folglich ist der Kleinste-Quadrate-Schätzer konsistent.
Die Eigenschaft besagt, dass mit steigender Stichprobengröße die Wahrscheinlichkeit, dass der Schätzer vom wahren Parameter abweicht, sinkt.
Normal lineares Modell
Zu dem bisherigen Modell
bzw.
,
dessen Annahmen sich wie folgt zusammenfassen ließen
,
wird hier zusätzlich von der Annahme ausgegangen, dass die Fehlerterme normalverteilt sind:
Dadurch ergibt sich das normal lineare Modell:
mit und
Maximum-Likelihood-Schätzung
Das normal lineare Modell lässt sich mithilfe der Maximum-Likelihood-Methode schätzen. Dazu wird zunächst die einzelne Wahrscheinlichkeitsdichte des Fehlervektors, der einer Normalverteilung folgt, benötigt. Sie lautet:
, wobei darstellt.
Da sich der Fehlerterm auch als darstellen lässt, kann man die einzelne Dichte auch schreiben als
.
Aufgrund der Unabhängigkeitsannahme lässt sich die gemeinsame Wahrscheinlichkeitsdichte als Produkt der einzelnen Randdichten darstellen. Die gemeinsame Dichte lautet bei unterstellter stochastischer Unabhängigkeit dann
Die gemeinsame Dichte lässt sich auch schreiben als:
Da wir uns nun nicht für ein bestimmtes Ergebnis bei gegebenen Parametern interessieren, sondern diejenigen Parameter suchen, die am besten zu unseren Daten passen, denen also die größte Wahrscheinlichkeit zugeordnet wird, dass sie den wahren Parametern entsprechen, lässt sich nun die Likelihood-Funktion als gemeinsame Wahrscheinlichkeitsdichte in Abhängigkeit der Parameter formulieren.
Durch Logarithmieren der Likelihood-Funktion ergibt sich die Log-Likelihood-Funktion in Abhängigkeit von den Parametern:
Diese Funktion gilt es nun bzgl. der Parameter zu maximieren. Es ergibt sich also folgendes Maximierungsproblem:
Beim partiellen Ableiten wird ersichtlich, dass der Ausdruck
bereits aus der Herleitung des KQ-Schätzers bekannt ist. Somit reduziert sich das Maximum-Likelihood-Opimierungsproblem auf das KQ-Optimierungsproblem. Daraus folgt, dass der KQ-Schätzer dem ML-Schätzer entspricht:
Der ML-Schätzer für die Varianz, der sich auch aus der zweiten partiellen Ableitung ergibt, lautet:
Der Wert der Log-Likelihood-Funktion, bewertet an der Stelle der geschätzten Koeffizienten:
Paneldatenregression
Das allgemeine lineare Paneldaten-Modell lässt zu, dass der Achsenabschnitt und die Steigungsparameter zum einen über die Individuen (in Querschnittsdimension) und zum anderen über die Zeit variieren (nicht-zeitinvariant). Das allgemeine lineare Paneldaten-Modell lautet:
mit der Varianz-Kovarianz-Matrix:
Hierbei ist eine skalar vorliegende abhängige Variable, ist ein -Vektor von unabhängigen Variablen, ist ein skalar vorliegender Fehlerterm.
Da dieses Modell zu allgemein ist und nicht schätzbar ist, wenn es mehr Parameter als Beobachtungen gibt, müssen bezüglich der Variation von und mit und und bezüglich des Verhaltens des Fehlerterms einschränkende Annahmen getroffen werden. Diese zusätzlichen Restriktionen und die darauf aufbauenden Modelle sind Themen der linearen Paneldatenmodelle und der Paneldatenanalyse.
Schätzung des Varianzparameters
Die Schätzwerte der berechnen sich mithilfe des KQ-Schätzers als
,
wobei man dies auch kürzer als
mit
schreiben kann. Die Matrix ist die Matrix der Orthogonalprojektion auf den Spaltenraum von und hat maximal den Rang . Sie wird auch Hat-Matrix genannt, weil sie "den Hut aufsetzt" und somit zum Schätzer macht.
Die Residuen werden ermittelt als
,
wobei mit vergleichbare Eigenschaften hat.
Da fest vorgegeben ist, kann man alle diese Variablen als lineare Transformation von und damit von darstellen, und deshalb können auch ihr Erwartungswertvektor und ihre Kovarianzmatrix unproblematisch ermittelt werden.
Die Quadratsumme (von engl. „residual sum of squares“) der Residuen ergibt in Matrix-Notation
.
Dies kann auch geschrieben werden als
.
Die Varianz wird mit Hilfe der Residuen geschätzt, und zwar als mittlere Quadratsumme der Residuen:
Schätzen und Testen
Für die inferentielle Regression (Schätzen und Testen) wird noch die Information über die Verteilung der Störgröße gefordert. Zusätzlich zu den bereits weiter oben aufgeführten Annahmen hat man hier als weitere Annahme:
D. h., die Störgrößen sind multivariat normalverteilt mit dem Erwartungswert und der Varianz-Kovarianz-Matrix , wobei den Nullvektor und die Einheitsmatrix der Dimension bezeichnet. Hier sind unkorrelierte Zufallsvariablen auch stochastisch unabhängig.
Da die interessierenden Schätzer zum größten Teil lineare Transformationen von sind, sind sie ebenfalls normalverteilt mit den entsprechenden Parametern. Ferner ist die Quadratsumme der Residuen als nichtlineare Transformation -verteilt mit Freiheitsgraden.
Hat man eine Regression ermittelt, ist man auch an der Güte dieser Regression interessiert. Im Fall für alle wird häufig als Maß für die Güte das Bestimmtheitsmaß verwendet. Generell gilt, je näher der Wert des Bestimmtheitsmaßes bei liegt, desto besser ist die Güte der Regression. Ist das Bestimmtheitsmaß klein, kann man seine Signifikanz durch das Hypothesenpaar gegen mit der Prüfgröße
testen. Die Prüfgröße ist F-verteilt mit und Freiheitsgraden. Überschreitet die Prüfgröße bei einem Signifikanzniveau den kritischen Wert , das -Quantil der F-Verteilung mit und Freiheitsgraden, wird abgelehnt. ist dann ausreichend groß, trägt also vermutlich genügend viel Information zur Erklärung von bei.
Unter den Voraussetzungen des klassischen linearen Regressionsmodells ist der Test ein Spezialfall der einfaktoriellen ANOVA. Für jeden Beobachtungswert ist die Störgröße und damit -verteilt (mit der wahre Regressionswert in der Grundgesamtheit), d. h., die Voraussetzungen der ANOVA sind erfüllt. Sind alle -Koeffizienten gleich null, so ist dies äquivalent zur Nullhypothese der ANOVA: .
Die Residualanalyse, bei der man die Residuen über den unabhängigen Variablen aufträgt, gibt Aufschluss über
die Richtigkeit des angenommenen linearen Zusammenhangs,
Ein Ziel bei der Residualanalyse ist es, die Voraussetzung der unbeobachteten Residuen zu überprüfen. Hierbei ist es wichtig zu beachten, dass
gilt. ist mit der Formel berechenbar. Im Gegensatz hierzu ist die Störgröße nicht berechenbar oder beobachtbar. Nach den oben getroffenen Annahmen soll für das Modell gelten
Es liegt somit eine Varianzhomogenität vor. Dieses Phänomen wird auch als Homoskedastizität bezeichnet und ist auf die Residuen übertragbar. Dies bedeutet: Wenn man die unabhängigen Variablen gegen die Residuen aufträgt, sollten keine systematischen Muster erkennbar sein.
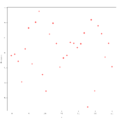
Beispiel 1 zur Residualanalyse
Beispiel 2 zur Residualanalyse
Beispiel 3 zur Residualanalyse
In den obigen drei Grafiken wurden die unabhängigen Variablen gegen die Residuen geplottet, und im Beispiel 1 sieht man, dass hier tatsächlich kein erkennbares Muster in den Residuen vorliegt, d. h., dass die Annahme der Varianzhomogenität erfüllt ist. In den Beispielen 2 und 3 dagegen ist diese Annahme nicht erfüllt: Man erkennt ein Muster. Zur Anwendung der linearen Regression sind daher hier zunächst geeignete Transformationen durchzuführen. So ist im Beispiel 2 ein Muster zu erkennen, das an eine Sinus-Funktion erinnert, womit hier eine Daten-Transformation der Form denkbar wäre, während im Beispiel 3 ein Muster zu erkennen ist, das an eine Parabel erinnert, in diesem Fall also eine Daten-Transformation der Form angebracht sein könnte.
Beitrag der einzelnen Regressoren zur Erklärung der abhängigen Variablen
Man ist daran interessiert, ob man einzelne Parameter oder Regressoren aus dem Regressionsmodell entfernen kann, ob also ein Regressor nicht (oder nur gering) zur Erklärung von beiträgt. Dies ist dann möglich, falls ein Parameter gleich null ist, somit testet man die Nullhypothese. Das heißt, man testet, ob der -te Parameter gleich Null ist. Wenn dies der Fall ist, kann der zugehörige -te Regressor aus dem Modell entfernt werden. Der Vektor ist als lineare Transformation von wie folgt verteilt:
Wenn man die Varianz der Störgröße schätzt, erhält man für die geschätzte Varianz-Kovarianz-Matrix
.
Die geschätzte Varianz eines Regressionskoeffizienten steht als -tes Diagonalelement in der geschätzten Varianz-Kovarianz-Matrix. Es ergibt sich die Prüfgröße
,
wobei die Wurzel der geschätzten Varianz des -ten Parameters dessen geschätzten Standardfehler darstellt.
Die Prüf- bzw. Pivotgröße ist t-verteilt mit Freiheitsgraden. Ist größer als der kritische Wert , dem -Quantil der -Verteilung mit Freiheitsgraden, wird die Hypothese abgelehnt. Somit wird der Regressor im Modell beibehalten und der Beitrag des Regressors zur Erklärung von ist signifikant groß, d. h. signifikant von null verschieden.
Prognose
Ein einfaches Modell zur Prognose von endogenen Variablen ergibt sich durch
,
wobei den Vektor von zukünftigen abhängigen Variablen und die Matrix der erklärenden Variablen zum Zeitpunkt darstellt.
Die Voraussage wird wie folgt dargestellt: , woraus sich folgender Voraussagefehler ergibt:
Eigenschaften des Voraussagefehlers:
Der Voraussagefehler ist im Mittel null:
Die Varianz-Kovarianz-Matrix des Voraussagefehlers lautet:
Ermittelt man einen Prognosewert, möchte man möglicherweise wissen, in welchem Intervall sich die prognostizierten Werte mit einer festgelegten Wahrscheinlichkeit bewegen. Man wird also ein Konfidenzintervall für den durchschnittlichen Prognosewert ermitteln. Im Fall der linearen Einfachregression ergibt sich für die Varianz des Prognosefehlers
.
Man erhält dann als -Konfidenzintervall für die Varianz des Prognosefehlers
.
Speziell für den Fall der einfachen linearen Regression ergibt sich das Prognoseintervall:[8]
Aus dieser Form des Konfidenzintervalls erkennt man sofort, dass das Konfidenzintervall breiter wird, wenn sich die exogene Prognosevariable vom „Gravitationszentrum“ der Daten entfernt. Schätzungen der endogenen Variablen sollten also im Beobachtungsraum der Daten liegen, sonst werden sie sehr unzuverlässig.
Modell mit einer nicht-skalaren Einheits-Kovarianzmatrix
Heteroskedastisches Modell
Falls die die Annahme der Homoskedastizität nicht erfüllt ist, d. h. die Diagonalelemente der Varianz-Kovarianz-Matrix nicht identisch sind, ergibt sich folgendes Modell:
mit
und
Allgemeine Varianz-Kovarianz-Matrix bei Heteroskedastizität:
Hierbei wird angenommen, dass eine bekannte, reelle, positiv definite und symmetrische Matrix der Dimension ist.
Falls die spezielle Form der multiplikativen Heteroskedastizität vorliegt, nimmt die allgemeine Varianz-Kovarianz-Matrix folgende Form an:
Verallgemeinerte Kleinste-Quadrate-Methode
Um die unbekannten Parameter im linearen Regressionsmodell effizient zu schätzen, kann die GLS-Methode (englisch für Generalized Least Squares) herangezogen werden. Diese Methode kann benutzt werden, falls ein bestimmter Grad an Korrelation zwischen den Residuen vorliegt, oder wenn Heteroskedastizität vorliegt, oder beides. Die GLS-Methode minimiert im Gegensatz zur KQ-Methode eine gewichtete Summe der quadrierten Residuen. Der GLS-Schätzer für den Parametervektor lautet:
Der GLS-Schätzer ist ebenfalls BLUE. Weitere Eigenschaften:
Varianz-Kovarianz-Matrix des GLS-Schätzers:
Der GLS-Schätzer ist erwartungstreu:
Im Velgleich des GLS-Schätzers mit dem OLS-Schätzer ergibt sich zwischen den Schätzern folgende Differenz:
Im Falle einer nicht-skalaren Varianz-Kovarianz-Matrix, wie sie bei der verallgemeinerten Kleinste-Quadrate-Methode zum Einsatz kommt, lässt sich die gemeinsame Dichte aus einer Maximum-Likelihood-Schätzung eines normal-linearen Modells schreiben als:
Beispiel
Zur Illustration der multiplen Regression wird im folgenden Beispiel untersucht, wie die abhängige Variable : Bruttowertschöpfung (in Preisen von 95; bereinigt, Mrd. Euro) von den unabhängigen Variablen „Bruttowertschöpfung nach Wirtschaftsbereichen Deutschland (in jeweiligen Preisen; Mrd. EUR)“ abhängt.
Die Daten sind im Portal Statistik zu finden.
Da man in der Regel die Berechnung eines Regressionsmodells am Computer durchführt, wird in diesem Beispiel exemplarisch dargestellt, wie eine multiple Regression mit der Statistik-SoftwareR durchgeführt werden kann.
Bruttowertschöpfung von Land- und Forstwirtschaft, Fischerei
Bruttowertschöpfung des produzierenden Gewerbes ohne Baugewerbe
Bruttowertschöpfung im Baugewerbe
Bruttowertschöpfung von Handel, Gastgewerbe und Verkehr
Bruttowertschöpfung durch Finanzierung, Vermietung und Unternehmensdienstleister
Bruttowertschöpfung von öffentlichen und privaten Dienstleistern
Zunächst lässt man sich ein Streudiagramm ausgeben. Es zeigt, dass die gesamte Wertschöpfung offensichtlich mit den Wertschöpfungen der wirtschaftlichen Bereiche positiv korreliert ist. Das erkennt man daran, dass die Datenpunkte in der ersten Spalte der Grafik in etwa auf einer Geraden mit einer positiven Steigung liegen. Auffällig ist, dass die Wertschöpfung im Baugewerbe negativ mit den anderen Sektoren korreliert. Dies erkennt man daran, dass in der vierten Spalte die Datenpunkte näherungsweise auf einer Geraden mit einer negativen Steigung liegen.
Streudiagramm der Regressionsvariablen
In einem ersten Schritt gibt man das Modell mit allen Regressoren in R ein:
Anschließend lässt man sich in R ein Summary des Modells mit allen Regressoren ausgeben, dann erhält man folgende Auflistung:
Residuals:
Min 1Q Median 3Q Max
−1.5465 −0.8342 −0.1684 0.5747 1.5564
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 145.6533 30.1373 4.833 0.000525 ***
BBLandFF 0.4952 2.4182 0.205 0.841493
BBProdG 0.9315 0.1525 6.107 7.67e−05 ***
BBBau 2.1671 0.2961 7.319 1.51e−05 ***
BBHandGV 0.9697 0.3889 2.494 0.029840 *
BBFinVerm 0.1118 0.2186 0.512 0.619045
BBDienstÖP 0.4053 0.1687 2.402 0.035086 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.222 on 11 degrees of freedom
Multiple R-Squared: 0.9889, Adjusted R-squared: 0.9828
F-statistic: 162.9 on 6 and 11 DF, p-value: 4.306e−10
Der Test auf Güte des gesamten Regressionsmodells ergibt eine Prüfgröße von . Diese Prüfgröße hat einen p-Wert von , somit ist die Anpassung signifikant gut.
Die Analyse der einzelnen Beiträge der Variablen (Tabelle Coefficients) des Regressionsmodells ergibt bei einem Signifikanzniveau von , dass die Variablen und offensichtlich die Variable nur unzureichend erklären können. Dies erkennt man daran, dass die zugehörigen -Werte zu diesen beiden Variablen verhältnismäßig klein sind, und somit die Hypothese, dass die Koeffizienten dieser Variablen null sind, nicht verworfen werden kann.
Die Variablen und sind gerade noch signifikant. Besonders stark korreliert ist (in diesem Beispiel also ) mit den Variablen und , was man an den zugehörigen hohen -Werten erkennen kann.
Im nächsten Schritt werden die nicht-signifikanten Regressoren und aus dem Modell entfernt:
lm(BWSb95~BBProdG+BBBau+BBHandGV+BBDienstÖP)
Anschließend lässt man sich wiederum ein Summary des Modells ausgeben, dann erhält man folgende Auflistung:
Residuals:
Min 1Q Median 3Q Max
−1.34447 −0.96533 −0.05579 0.82701 1.42914
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 158.00900 10.87649 14.528 2.05e−09 ***
BBProdG 0.93203 0.14115 6.603 1.71e−05 ***
BBBau 2.03613 0.16513 12.330 1.51e−08 ***
BBHandGV 1.13213 0.13256 8.540 1.09e−06 ***
BBDienstÖP 0.36285 0.09543 3.802 0.0022 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.14 on 13 degrees of freedom
Multiple R-Squared: 0.9886, Adjusted R-squared: 0.985
F-statistic: 280.8 on 4 and 13 DF, p-value: 1.783e−12
Dieses Modell liefert eine Prüfgröße von . Diese Prüfgröße hat einen p-Wert von , somit ist die Anpassung besser als im ersten Modell. Dies ist vor allem darauf zurückzuführen, dass in dem jetzigen Modell alle Regressoren signifikant sind.
Regularisierung der Regression
Um ein gewünschtes Verhalten der Regression zu gewährleisten und somit eine Überanpassung an den Trainingsdatensatz zu vermeiden, gibt es die Möglichkeit, den Regressionsterm mit Penalty-Termen zu versehen, die als Nebenbedingungen auftreten.
Die -Regularisierung (auch LASSO-Regularisierung genannt): Durch werden bevorzugt einzelne Elemente des Vektors minimiert. Die übrigen Elemente des Vektors können jedoch (betragsmäßig) große Werte annehmen. Dies begünstigt die Bildung dünnbesetzter Matrizen, was effizientere Algorithmen ermöglicht.
Die -Regularisierung (auch Ridge-Regularisierung genannt): Durch wird der gesamte Vektor gleichmäßig minimiert, die Matrizen sind jedoch voller.
Das elastische Netz: Hierbei wird durch den Ausdruck sowohl die - als auch die-Regularisierung durchgeführt.
Lineare Modelle lassen sich dahingehend erweitern, dass keine feste Designmatrix untersucht wird, sondern auch diese zufallsbehaftet ist. Die Untersuchungsmethoden ändern sich in diesem Fall nicht substantiell, werden aber deutlich komplizierter und damit rechenaufwendiger.
Spezielle Anwendungen der Regressionsanalyse
Spezielle Anwendungen der Regressionsanalyse beziehen sich auch auf die Analyse von diskreten und im Wertebereich eingeschränkten abhängigen Variablen. Hierbei kann unterschieden werden nach Art der abhängigen Variablen und Art der Einschränkung des Wertebereichs. Im Folgenden werden die Regressionsmodelle, die an dieser Stelle angewandt werden können, aufgeführt. Nähere Angaben hierzu finden sich bei Frone (1997)[11] sowie Long (1997)[12].
↑M. R. Frone: Regression models for discrete and limited dependent variables. Research Methods Forum No. 2, 1997, online. (Memento vom 7. Januar 2007 im Internet Archive).
↑J. S. Long: Regression models for categorical and limited dependent variables. Sage, Thousand Oaks, CA 1997.
Norman R. Draper, Harry Smith: Applied Regression Analysis. Wiley, New York 1998.
Ludwig Fahrmeir, Thomas Kneib, Stefan Lang: Regression: Modelle, Methoden und Anwendungen. Springer Verlag, Berlin / Heidelberg/ New York 2007, ISBN 978-3-540-33932-8.
Gerhard Opfer: Numerische Mathematik für Anfänger. 2. Auflage. Vieweg Verlag, 1994.
Volker Oppitz, Volker Nollau: Taschenbuch Wirtschaftlichkeitsrechnung. Carl Hanser Verlag, 2003, ISBN 3-446-22463-7.
Volker Oppitz: Gabler Lexikon Wirtschaftlichkeitsrechnung. Gabler-Verlag, 1995, ISBN 3-409-19951-9.
Peter Schönfeld: Methoden der Ökonometrie. Berlin/Frankfurt 1969.
Dieter Urban, Jochen Mayerl: Regressionsanalyse: Theorie, Technik und Anwendung. 2. überarb. Auflage. VS Verlag, Wiesbaden 2006, ISBN 3-531-33739-4.
E. Zeidler (Hrsg.): Taschenbuch der Mathematik. (Bekannt als Bronstein und Semendjajew.) Stuttgart/Leipzig/Wiesbaden 2003.






















![{\displaystyle \forall i\neq j\colon \operatorname {Cov} (\varepsilon _{i},\varepsilon _{j})=\operatorname {E} [(\varepsilon _{i}-\operatorname {E} (\varepsilon _{i}))((\varepsilon _{j}-\operatorname {E} (\varepsilon _{j}))]=\operatorname {E} (\varepsilon _{i}\varepsilon _{j})=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eaba5f0b18e5677c0bf1a2d76269a439d39d2ba5)
![{\displaystyle \forall i\colon \operatorname {Var} (\varepsilon _{i})=\operatorname {E} [(\varepsilon _{i}-\operatorname {E} (\varepsilon _{i}))^{2}]=\sigma ^{2}=\mathrm {const.} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/a09d8a986434128c0472ff0ad5dfbb1eefc72706)














![{\displaystyle b_{2}={\frac {n\cdot \mathbf {x} ^{T}\mathbf {y} -1\!\!1^{T}\mathbf {x} \cdot 1\!\!1^{T}\mathbf {y} }{n\cdot \mathbf {x} ^{T}\mathbf {x} -(1\!\!1^{T}\mathbf {x} )^{2}}}={\frac {\sum \limits _{i=1}^{n}(x_{i}-{\bar {x}})(y_{i}-{\bar {y}})}{\sum \limits _{i=1}^{n}(x_{i}-{\bar {x}})^{2}}}={\frac {\operatorname {Cov} [x,y]}{\operatorname {Var} [x]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6186485aca8b9df215af407ec4b33d8caf19ad50)































































































































![{\displaystyle {\mbox{Cov}}({\boldsymbol {\varepsilon }}):=\operatorname {E} [({\boldsymbol {\varepsilon }}-E({\boldsymbol {\varepsilon }}))({\boldsymbol {\varepsilon }}-\operatorname {E} ({\boldsymbol {\varepsilon }})^{T}]=\operatorname {E} ({\boldsymbol {\varepsilon }}{\boldsymbol {\varepsilon }}^{T})={\begin{pmatrix}\operatorname {Var} [\varepsilon _{1}]&\operatorname {Cov} [\varepsilon _{1},\varepsilon _{2}]&\cdots &\operatorname {Cov} [\varepsilon _{1},\varepsilon _{T}]\\\\\operatorname {Cov} [\varepsilon _{2},\varepsilon _{1}]&\operatorname {Var} [\varepsilon _{2}]&\cdots &\operatorname {Cov} [\varepsilon _{2},\varepsilon _{T}]\\\\\vdots &\vdots &\ddots &\vdots \\\\\operatorname {Cov} [\varepsilon _{T},\varepsilon _{1}]&\operatorname {Cov} [\varepsilon _{T},\varepsilon _{2}]&\cdots &\operatorname {Var} [\varepsilon _{T}]\end{pmatrix}}=\sigma ^{2}{\begin{pmatrix}1&0&\cdots &0\\0&1&\ddots &\vdots \\\vdots &\ddots &\ddots &0\\0&\cdots &0&1\end{pmatrix}}_{(T\times T)}=\sigma ^{2}\mathbf {I} _{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d295a1af28c581b75b5bf90f98f681dd91f99ee7)












![{\displaystyle \operatorname {Cov} (\mathbf {b} )=\operatorname {E} \left[(\mathbf {b} -\operatorname {E} (\mathbf {b} ))(\mathbf {b} -\operatorname {E} (\mathbf {b} ))^{T}\right]=\operatorname {E} \left[(\mathbf {X} ^{T}\mathbf {X} )^{-1}\mathbf {X} ^{T}{\boldsymbol {\varepsilon }}{\boldsymbol {\varepsilon }}^{T}\mathbf {X} (\mathbf {X} ^{T}\mathbf {X} )^{-1}\right]=(\mathbf {X} ^{T}\mathbf {X} )^{-1}\mathbf {X} ^{T}\underbrace {\operatorname {E} (\mathbf {\boldsymbol {\varepsilon }} {\boldsymbol {\varepsilon }}^{T})} _{\sigma ^{2}\mathbf {I} _{T}}\mathbf {\mathbf {X} } (\mathbf {X} ^{T}\mathbf {X} )^{-1}=\sigma ^{2}(\mathbf {X} ^{T}\mathbf {X} )^{-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a66bc99e435c3d59e41dcca4fc9aaa905caf437b)
![{\displaystyle {\begin{aligned}\operatorname {Cov} (\mathbf {b} )&={\begin{pmatrix}\operatorname {E} [(b_{1}-\operatorname {E} (b_{1}))(b_{1}-\operatorname {E} (b_{1}))]&\operatorname {E} [(b_{1}-\operatorname {E} (b_{1}))(b_{2}-\operatorname {E} (b_{2}))]&\cdots &\operatorname {E} [(b_{1}-\operatorname {E} (b_{1}))(b_{K}-\operatorname {E} (b_{K}))]\\\\\operatorname {E} [(b_{2}-\operatorname {E} (b_{2}))(b_{1}-\operatorname {E} (b_{1}))]&\operatorname {E} [(b_{2}-\operatorname {E} (b_{2}))(b_{2}-\operatorname {E} (b_{2}))]&\cdots &\operatorname {E} [(b_{2}-\operatorname {E} (b_{2}))(b_{K}-\operatorname {E} (b_{K}))]\\\\\vdots &\vdots &\ddots &\vdots \\\\\operatorname {E} [(b_{K}-\operatorname {E} (b_{K}))(b_{1}-\operatorname {E} (b_{1}))]&\operatorname {E} [(b_{K}-\operatorname {E} (b_{K}))(b_{2}-\operatorname {E} (b_{2}))]&\cdots &\operatorname {E} [(b_{K}-\operatorname {E} (b_{K}))(b_{K}-\operatorname {E} (b_{K}))]\end{pmatrix}}\\\\&={\begin{pmatrix}\operatorname {Var} [b_{1}]&\operatorname {Cov} [b_{1},b_{2}]&\cdots &\operatorname {Cov} [b_{1},b_{K}]\\\\\operatorname {Cov} [b_{2},b_{1}]&\operatorname {Var} [b_{2}]&\cdots &\operatorname {Cov} [b_{2},b_{K}]\\\\\vdots &\vdots &\ddots &\vdots \\\\\operatorname {Cov} [b_{K},b_{1}]&\operatorname {Cov} [b_{K},b_{2}]&\cdots &\operatorname {Var} [b_{K}]\end{pmatrix}}_{(K\times K)}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6b8d35f13c589b4b0ff54be51cf22347b1541ea5)


























































































 Beispiel 1 zur Residualanalyse
Beispiel 1 zur Residualanalyse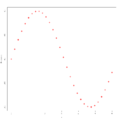 Beispiel 2 zur Residualanalyse
Beispiel 2 zur Residualanalyse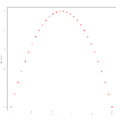 Beispiel 3 zur Residualanalyse
Beispiel 3 zur Residualanalyse
























![{\displaystyle \operatorname {E} [({\hat {\mathbf {y} }}_{0}-\mathbf {y} _{0}-\operatorname {E} ({\hat {\mathbf {y} }}_{0}-\mathbf {y} _{0}))(({\hat {\mathbf {y} }}_{0}-\mathbf {y} _{0}-\operatorname {E} ({\hat {\mathbf {y} }}_{0}-\mathbf {y} _{0}))^{T}]=\sigma ^{2}[\mathbf {X} _{0}(\mathbf {X} ^{T}\mathbf {X} )^{-1}\mathbf {X} _{0}^{T}+\mathbf {I} ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be34f7fd73f73f8993c43d00c620e5c86d6fd87d)


![{\displaystyle [{\hat {y}}_{0}-t_{1-\alpha /2;T-K}\cdot {\sqrt {\operatorname {Var} ({\hat {y}}_{0}-y_{0})}}\;;\;{\hat {y}}_{0}+t_{1-\alpha /2;T-K}\cdot {\sqrt {\operatorname {Var} ({\hat {y}}_{0}-y_{0})}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/79e2763cf4dc0c7231990a51864e2c79419254a7)
![{\displaystyle \left[{\hat {y}}_{0}-t_{1-\alpha /2;T-K}\cdot {\sqrt {\sigma ^{2}\left(1+{\frac {1}{T}}+{\frac {(x_{0}-{\bar {x}})^{2}}{\sum \limits _{t=1}^{T}(x_{t}-{\bar {x}})^{2}}}\right)}}\;;\;{\hat {y}}_{0}+t_{1-\alpha /2;T-K}\cdot {\sqrt {\sigma ^{2}\left(1+{\frac {1}{T}}+{\frac {(x_{0}-{\bar {x}})^{2}}{\sum \limits _{t=1}^{T}(x_{t}-{\bar {x}})^{2}}}\right)}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5b7e91d69b0482bef974e1cf1150ee51998b6417)










![{\displaystyle \delta =\operatorname {Cov} ({\hat {\boldsymbol {\beta }}}_{\text{GLS}})-\operatorname {Cov} (\mathbf {b} )=\sigma ^{2}[(\mathbf {X} ^{T}\mathbf {X} )^{-1}\mathbf {X} ^{T}\mathbf {\Psi } \mathbf {X} (\mathbf {X} ^{T}\mathbf {X} )^{-1}-(\mathbf {X} ^{T}\mathbf {\Psi } ^{-1}\mathbf {X} )^{-1}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/58a0561df66b6d5701e6ec099617fba6e9f1f67a)




















{kind=link}
{kind=link}